客户端架构
概述
在执行层客户端的核心职责——交易执行之外,它还承担了若干关键责任。这些包括验证区块链数据并存储其本地副本,通过 Gossip 协议与其他执行层客户端进行网络通信,维护交易池,以及满足共识层的需求。这种多层次的操作确保了以太坊网络的稳健性和完整性。
客户端架构基于多种特定标准构建,每种标准在整体功能中都扮演着独特角色。执行引擎位于架构的顶部,驱动执行层,而执行层则由共识层驱动。执行层运行在 DevP2P 网络层之上,并通过提供合法的引导节点(boot nodes)作为进入网络的初始接入点。当我们调用一个引擎 API 方法(例如 fork choice updated)时,可以通过我们选择的同步模式订阅相关的主题,从对等节点下载区块。
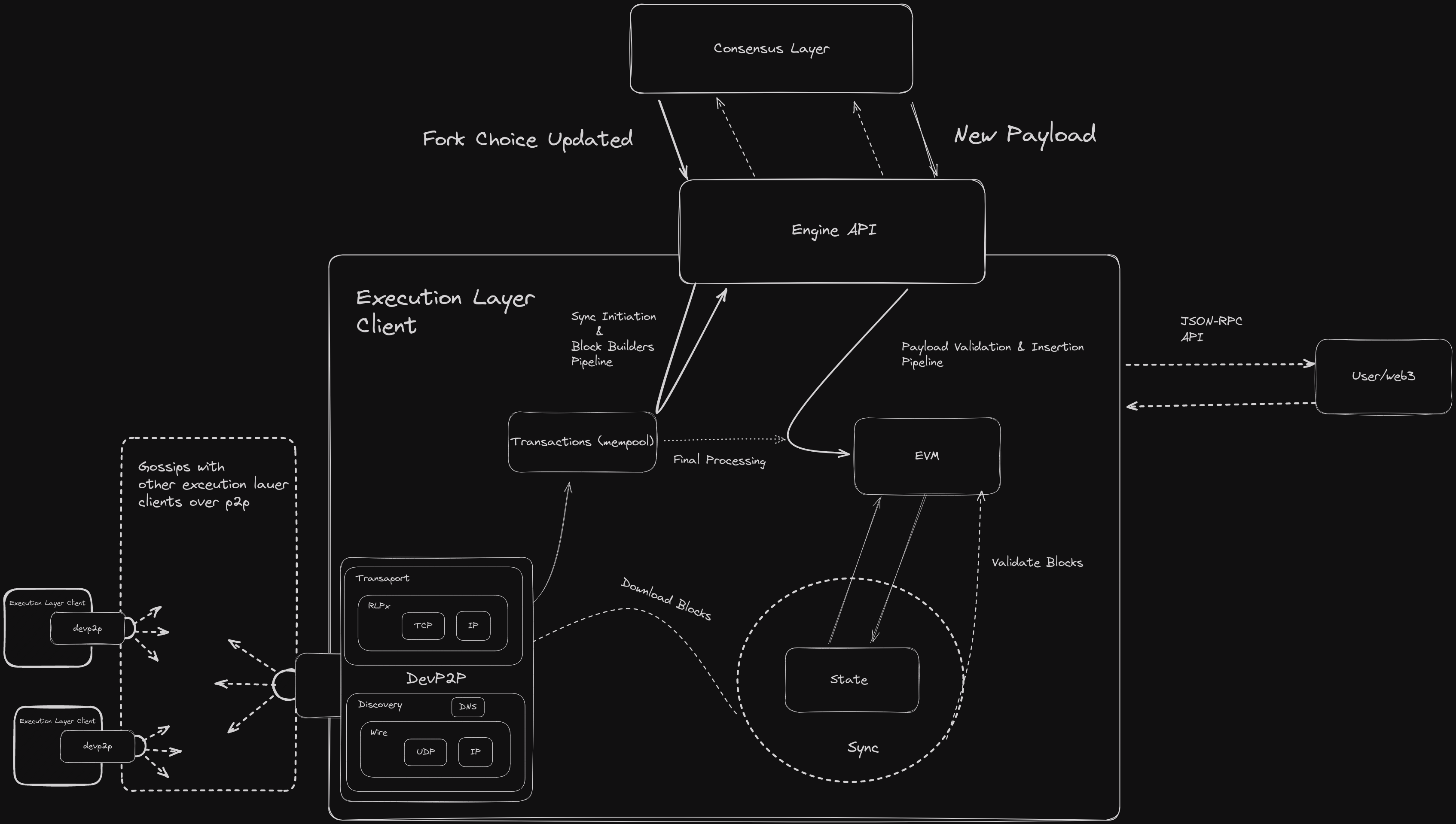
上图展示了执行层客户端的简化架构,省略了一些组件。
EVM
以太坊围绕一个虚拟化的中央处理单元(CPU)构建。计算机在硬件层面有自己的 CPU,例如 x86、ARM、RISC-V 等。每种处理器架构都有独特的指令集,用于执行诸如算术、逻辑和数据处理等任务,使计算机成为通用计算设备。因此,当使用硬件层面的指令集执行程序时,结果可能会因硬件的不同而有所变化。在计算机科学中,我们通过创建虚拟机(例如 JVM)来虚拟化指令集,以确保无论底层硬件如何,执行结果都一致。 EVM 是专为以太坊程序设计的虚拟化执行引擎,它确保了执行结果一致性,并在所有以太坊客户端之间就计算结果达成共识。
此外,以太坊采用了一种“sandwich complexity model”的设计哲学。这意味着外层应该简单,而所有的复杂性都集中在中间层。在这个框架下, EVM 的代码可以被视为最外层,而高层语言(如 Solidity)可以视为顶层。中间有一个复杂的编译器,将 Solidity 代码转换为 EVM 的字节码。
状态(State)
以太坊是一个通用的计算系统,作为状态机运行,这意味着它可以根据接收到的输入在多个状态之间转换。此外,以太坊与其他区块链(如比特币)显著不同,因为它维护了全局状态,而比特币仅维护全局未花费交易输出(UTXOs)。“状态”指的是数据、数据结构(如 Merkle-Patricia Trie)以及存储各种信息的数据库的综合集合。这包括地址、余额、合约代码和数据,以及当前的状态和网络状态。
交易(Transactions)
EVM 通过称为状态转换的过程生成数据并修改以太坊网络的状态。状态转换由交易触发,这些交易在 EVM 中处理。如果交易被视为合法,它将导致以太坊网络的状态发生变化。
DevP2P
这是执行层客户端与其他客户端通信的接口。交易最初存储在交易池(mempool)中,作为所有传入交易的存储库。执行层客户端通过点对点通信将这些交易传播给网络中的其他执行层客户端。网络上的交易接收方会确认其合法性,然后再广播至整个网络。
JSON-RPC API
当使用钱包或去中心化应用(DApp)时,我们通过标准化的 JSON-RPC API 与执行层通信。这使我们可以从外部查询以太坊的状态或发送交易(由钱包签名),随后由执行层客户端验证并传播到整个网络。
引擎 API
这是共识层与执行层之间交互的唯一接口。执行层通过引擎 API 向共识层提供两个主要的端点:fork choice updated 和 new payload。共识层通过这两个端点(每个都有 V1 到 V3 三个版本)来调用执行层的两个主要功能:
- New Payload (V1/V2/V3):共识层调用此接口来请求执行层验证和插入有效载荷。
- Fork Choice Updated (V1/V2/V3):共识层调用此接口来触发执行层进行状态同步和区块构建。
同步(Sync)
为了正确处理以太坊上的交易,我们必须对网络的全局状态达成共识,而不仅仅依赖于本地视角。执行层客户端的全局状态同步由共识层的 LMD-GHOST 算法的 fork choice 规则触发,并通过引擎 API 的 fork choice updated 端点传递到执行层。同步包括两个过程:从对等方下载远程区块并在 EVM 中验证它们。
架构组件
引擎(Engine)
执行层客户端充当“执行引擎”,并通过 Engine API 提供一个认证端点,与共识层客户端连接。执行层客户端只能由单一的共识层驱动,但一个共识层客户端实现可以连接多个执行层客户端以实现冗余。Engine API 通过 HTTP 使用 JSON-RPC 接口,并需要通过 JWT 令牌进行身份验证。此外,Engine JSON-RPC 仅暴露给共识层,但 JWT 主要用于验证有效载荷的来源是共识层客户端,并不加密流量。
例程
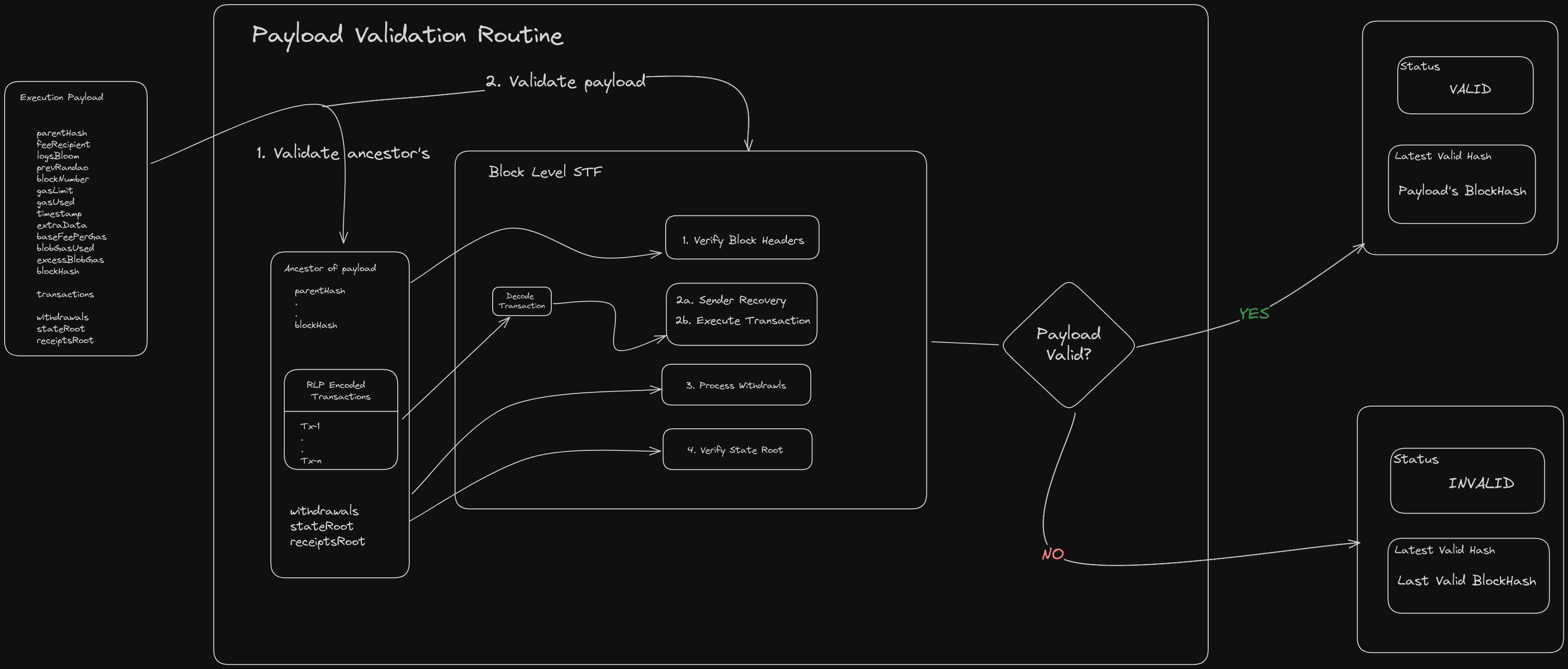
有效载荷验证(Payload validation)
有效载荷根据区块头和执行环境规则进行验证:
在以太坊合并后,执行层的功能在以太坊网络中发生了变化。此前,它负责管理区块链的共识,确保区块的正确顺序以及处理重组。然而,在合并后,这些任务被转交给共识层,从而显著简化了执行层。现在,我们可以将执行层视为主要执行状态转换功能。
为了更好地理解上述概念,有必要从共识层的角度审视执行层。共识规范在 deneb beacon 链规范中定义了执行载荷的处理过程,该过程在 beacon 链进行区块验证和共识层推进时执行。执行层在这里由 execution_engine 函数表示,该函数充当共识层与执行层之间的通信接口,具有许多复杂的实现。
在执行载荷处理过程中,我们首先进行几个高级检查,包括验证父哈希的准确性以及验证时间戳。此外,我们执行各种轻量级验证。随后,我们将载荷传输到执行层,在那里进行区块验证。notify payload 函数是最低级别的函数,充当共识层与执行引擎之间的接口。它仅包含函数签名,不包含任何实现细节。其唯一目的是将执行载荷传输到执行引擎,执行引擎充当执行层的客户端。执行引擎随后执行实际的状态转换函数,该函数涉及验证区块头的准确性并确保交易正确应用于状态。执行引擎最终将返回一个布尔值,表示状态转换是否成功。从共识层的角度来看,这仅仅是区块的验证。
这是一个简化版的区块级状态转换函数(stf)的 go 语言实现,该函数是区块验证和插入管道中的关键组件。虽然这个例子来自 Geth,但它代表了所有客户端中状态转换函数的基本工作方式。值得注意的是,除了 EELS python 规范客户端外,其他客户端的代码中很少直接使用"状态转换函数"这个名称,因为这个功能实际上被分散到了客户端架构的多个组件中。
func stf(parent types.Block, block types.Block, state state.StateDB) (state.StateDB, error) { //1
if err := core.VerifyHeaders(parent, block); err != nil { //2
// header error detected
return nil, err
}
for _, tx := range block.Transactions() { //3
res, err := vm.Run(block.header(), tx, state)
if err != nil {
// transaction invalid, block is invalid
return nil, err
}
state = res
}
return state, nil
}
-
状态转换函数的参数和返回值
- 在这个上下文中,我们检查父区块和当前区块,以验证从父区块到当前区块的某些转换逻辑。
- 我们将状态数据库(state DB)作为参数输入,其中包含与父区块相关的所有状态数据。这代表了最新的有效状态。
- 我们返回代表状态转换后更新状态的状态数据库(state DB)。
- 如果状态转换失败,我们不会更新状态数据库并返回错误。
-
状态转换函数的过程:首先验证区块头
- 以区块头验证失败的一个例子为例,我们可以考虑“gas limit”(汽油限制)字段,这一字段在历史上也具有重要意义。目前,汽油限制约为 3000 万。需要注意的是,汽油限制在执行层中并不是固定的。区块生产者可以通过一种方法修改汽油限制,使其增加或减少上一区块汽油限制的 1/1024。因此,如果你在单个区块中将汽油限制从 3000 万提升到 4000 万,则区块头验证将失败,因为它超过了 3000 万加上其 1/1024 的阈值。
- 其他区块头验证失败的实例包括区块号不按顺序排列的情况。通常,这种不一致由beacon 链负责检测,但在某些情况下,也可能在这个阶段被检测到。失败还可能发生在 1559 基准费用未根据上一次的汽油使用量与汽油限制的比较准确更新时。
-
在区块头验证完成后,我们将区块头中的环境视为应执行交易的环境,并开始应用交易。我们对区块中的交易逐一迭代,并在 EVM 中执行每笔交易。
- 区块头被传递给 EVM,以提供处理交易所需的上下文。此上下文包括诸如 coinbase(矿工奖励地址)、汽油限制和时间戳等指令,这些是正确执行交易所需的。
- 此外,我们传入交易和状态。
- 如果执行失败,我们仅返回错误,表明区块中存在无效交易,从而使整个区块无效。在执行层中,区块中任何错误都会使整个区块无效,因为它会污染整个区块。
- 一旦确认交易的有效性,我们会用结果更新状态。此时的状态代表了应用了新块中所有交易后的累积状态。
从 beacon 链的角度来看,上述的状态转换函数由 new payload 函数的调用来实现。
func newPayload(execPayload engine.ExecutionPayload) bool {
if _, err := stf(..); err != nil {
return false
}
return true
}
beacon 链调用 new payload 函数并传递执行载荷作为参数。在执行层,我们使用执行载荷中的信息调用状态转换函数。如果状态转换函数没有产生错误,我们返回 true。否则,返回 false 表示区块无效。
Geth
TODO: 添加 Geth 中状态转换函数的代码链接和详细说明
查看 lightclient 第二周的演讲获取概述。
同步
执行客户端通过从对等节点下载区块数据并使用区块验证规则验证它们来同步链。当区块链数据被验证且客户端追上链的最新状态时,同步完成,这使得能够构建最新状态。
由于从创世区块开始逐个验证区块和交易效率低下,执行层客户端采用其他策略来安全地同步到链的最新状态,例如快照同步(snap sync)。
载荷构建
更多详情请参见区块生产
方法
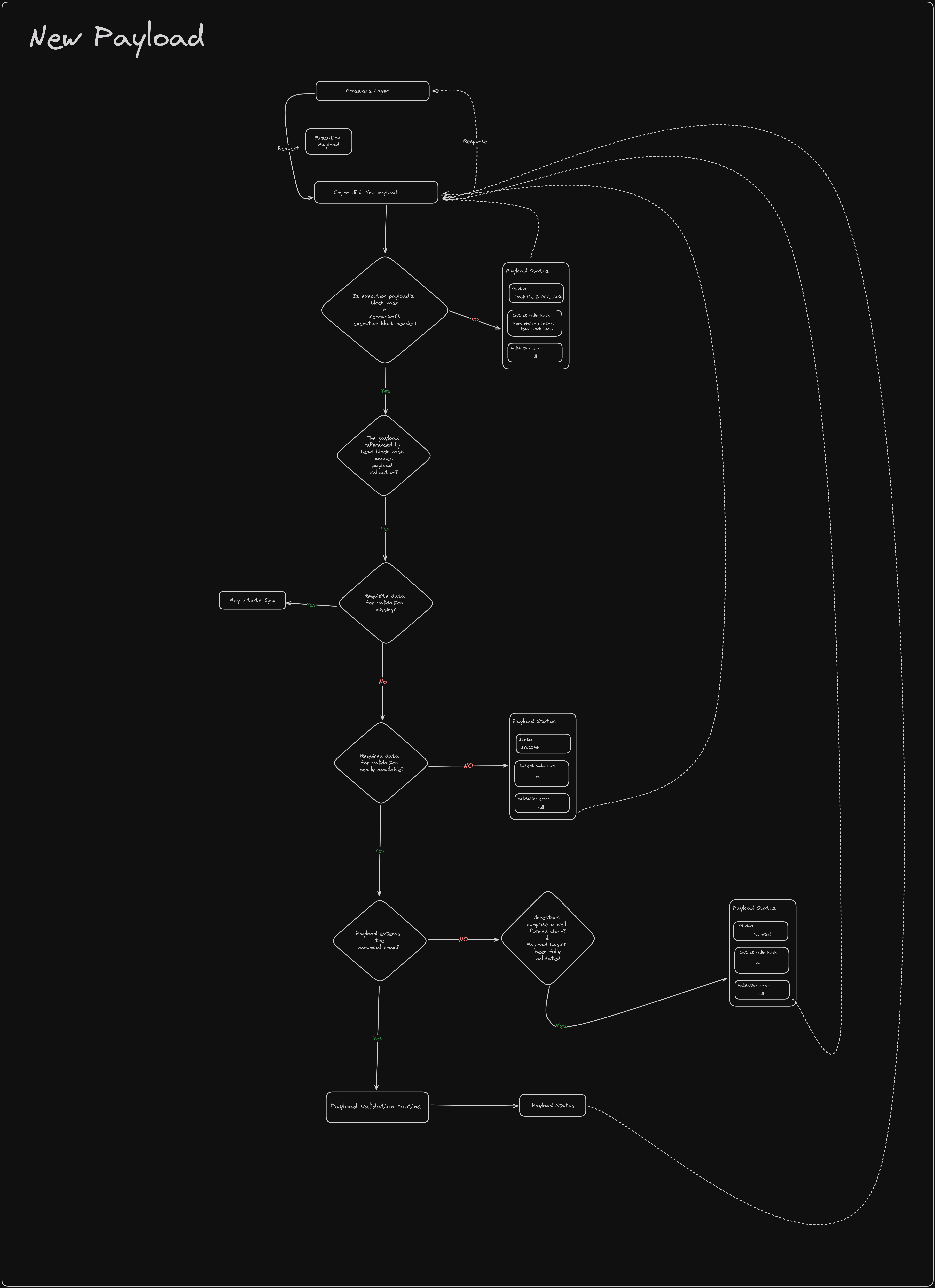
New payload
验证之前由载荷构建例程构建的载荷。
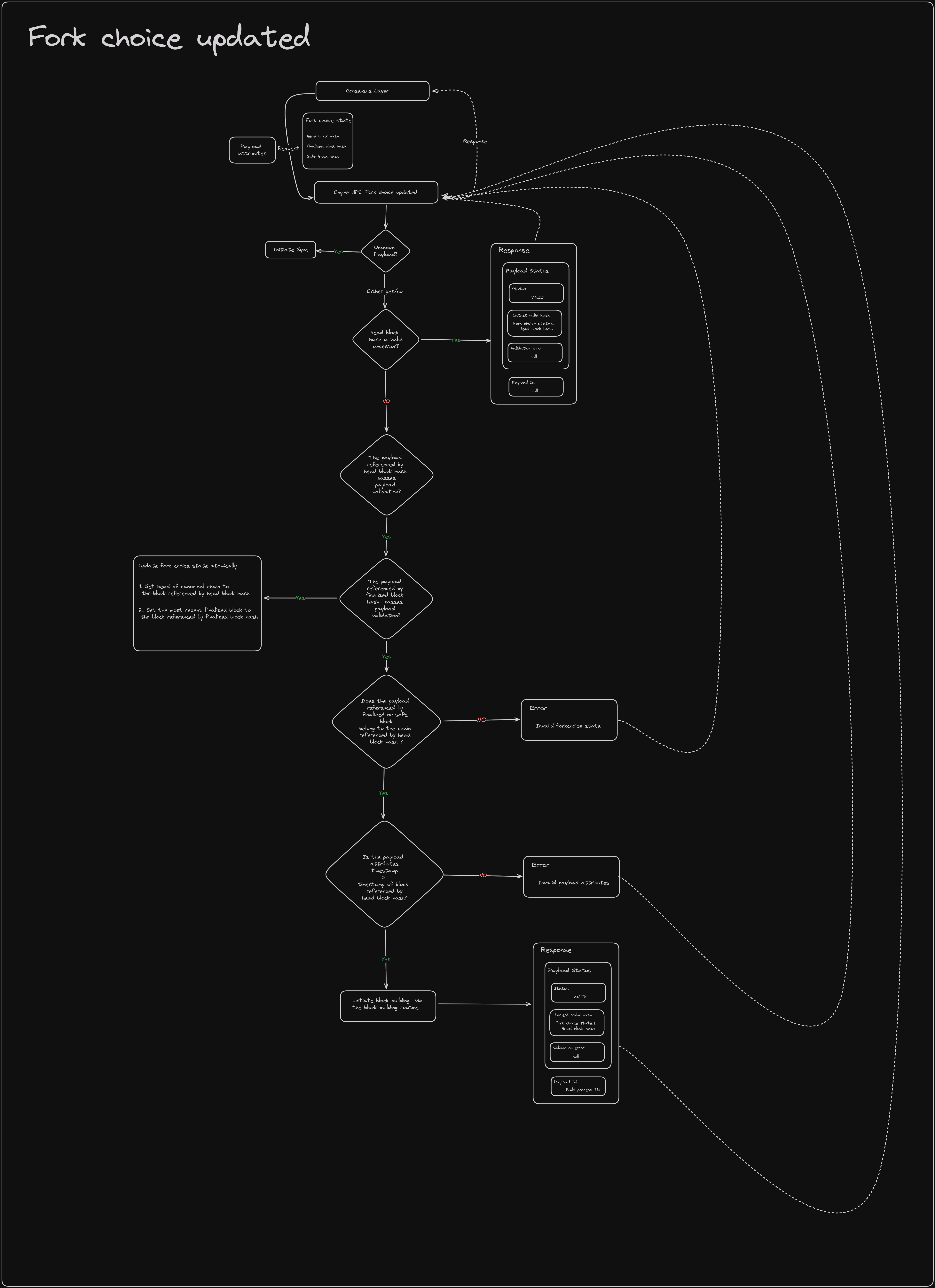
Fork choice updated
权益证明 LMD-GHOST 分叉选择规则和载荷构建的例程。
内部共识引擎
执行层有自己的共识引擎,用于与 beacon 链的副本一起工作。执行层的共识引擎被称为 ethone,具有共识层完整共识引擎一半的功能。
| 功能 | Beacon (权益证明) | Clique (权威证明) | Ethash (Proof-of-work) |
|---|---|---|---|
| Author: 区块铸造者的以太坊地址 | 如果区块头被识别为 PoS 区块头(难度值为 0),我们将获取区块头的 coinbase。否则,我们将区块头转发给 beacon 的 ethone 引擎(clique 或 ethash)进行进一步处理。 | 获取创建区块的账户地址。通过 ecrecover 从区块头的 extraData 中恢复公钥。 | |
| Verify Header(s): 处理一批区块头并根据当前共识引擎的规则验证它们 | 根据最终总难度将区块头分为 TTD 前后两批。使用 ethone 引擎验证 TTD 之前的批次,使用 beacon 验证之后的批次。 | ||
| 我们执行类似于执行层规范中的区块头验证。 | 验证区块头的时间戳不大于系统时间。 | ||
| 对于检查点区块(epoch 的第一个 slot),确保没有受益人。 | |||
| 区块头 nonce 可以有两个值:0x00..0 表示添加签名者的投票,0xff..f 表示删除签名者的投票。在检查点只能投票删除签名者。 | |||
| extraData 长度必须包含 vanity + 签名。在检查点,extraData 包含签名者列表 + 签名。 | |||
| 执行区块头 gas 检查。 | |||
| 获取快照。 | |||
| 在检查点区块验证快照中的签名者与 extraData。 | |||
| 调用 verify Seal 函数确定区块头中包含的签名是否满足所有条件。恢复过程涉及从区块头和 Clique 对象中的最近签名者列表提取信息。然后验证签名者是否包含在快照中。 | |||
| Verify Uncles: 验证叔块 | 如果是 PoS 区块头,检查叔块长度为 0。如果不是 PoS 区块头,通过 ethone 引擎验证叔块。 | Clique 中不应该存在叔块 | |
| Prepare: 初始化区块头的共识字段 | 如果达到 TTD,我们将区块头的难度设置为 beacon 的难度 0,否则调用 ethone 的 prepare | 通过提供父哈希和编号创建投票快照。在反向迭代过程中,我们从区块号开始向后遍历。如果到达创世区块、使用不存储父区块的轻客户端、向后到达 epoch,或者遍历的区块头超过软终局值(表示该段被认为是不可变的),我们就停止迭代。在停止迭代的检查点创建快照。 | |
| 如果我们在 epoch 结束时,我们将遍历 snap 对象的 proposals 字段中的地址,随机选择一个作为 coinbase。如果提案被授权,我们将投出授权票;否则,我们将投出删除票。 | |||
| 根据签名者的轮次设置区块头难度(如果签名者轮到则为 2,否则为 1) | |||
| 验证 extraData 包含所有必要元素,包括 extraVanity 和如果区块发生在 epoch 结束时的签名者列表。这被添加到区块头的 extraData 字段。 | |||
| Finalize: 对状态进行更改后,可能会更新状态数据库,但这个操作不涉及区块的组装 | 如果区块头不是 PoS 区块头,我们执行 ethone 的 finalize 函数。否则,我们遍历区块中的提款,将其金额从 wei 转换为 gwei。然后我们通过将转换后的金额添加到与当前提款关联的地址来修改状态。 | Clique 没有后交易共识规则,权威证明中没有区块奖励 | |
| FinalizeAndAssemble: 完成并组装最终区块 | 如果区块头不是 PoS 区块头,我们调用 ethone 的 FinalizeAndAssemble。如果没有提款且区块在上海分叉之后,我们包含一个空的提款对象。接下来,我们调用 finalize 函数计算状态根。然后我们将这个值分配给区块头对象的 root 属性。最后,我们通过组合区块头、交易、叔块、收据和提款来构造新区块。 | 验证没有提款,调用 finalize 函数,计算我们的 stateDB 的状态根,并将其分配给区块头。使用区块头、交易和收据构造新区块。 | |
| Seal: 生成区块的密封请求并将请求推送到给定通道 | 如果区块头不是 PoS 区块头,我们调用 ethone 的 seal。否则,我们不采取任何操作并返回 nil。密封的验证由共识层执行。 | 确保区块不是初始区块,获取快照,并确认我们有权签名且不包含在最近签名者列表中。协调我们各自轮次的时间,应用签名函数进行签名,并通过指定通道传输安全密封的区块。 | |
| SealHash: 密封前区块的哈希 | |||
| CalcDifficulty: 难度调整算法,返回新区块的难度 |
Client code
| EELS(cancun) | Geth | Reth | Erigon | Nethermind | Besu | |
|---|---|---|---|---|---|---|
| validate_header | ||||||
| validate_header -> calculate_base_fee_per_gas -> ensure | ||||||
| '' | ||||||
| calculate_base_fee_per_gas -> check_gas_limit | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| validate_header-> ensure | ||||||
| (this is stale , beacon chain provides this now) | ||||||
| ensure |
下载器
交易池
以太坊中主要有两种类型的交易池:
-
Legacy 池:由 Geth 管理,这些池使用基于价格排序的堆或优先队列来组织交易。具体来说,交易使用两个堆来组织:一个优先考虑即将到来的区块的有效小费,另一个关注 gas 费用上限。在交易池饱和期间,会选择这两个堆中较大的一个来驱逐交易,从而优化池的效率和响应性。紧急和浮动堆(urgent and floating heaps)
-
Blob 池:与传统池不同,blob 池维护一个采用不同机制剔除交易的优先堆。值得注意的是,blob 池的实现有详细的文档,可以在这里查看详细的注释说明。blob 池的一个关键特征是在其驱逐队列中使用对数函数。
EVM
Wiki - EVM TODO: 将规范中的相关代码移至 EVM
DevP2P
数据结构
更多详情请参见执行层数据结构页面。
存储
执行客户端处理的区块链和状态数据需要存储在磁盘上。这些数据对于验证新区块、验证历史记录以及为网络中的对等节点提供服务都是必需的。客户端存储历史数据(也称为远古数据库),其中包括以前的区块。另一个具有 trie 结构的数据库包含当前状态和少量最近的状态。实际上,客户端为不同的数据类别维护各种数据库。每个客户端可以实现不同的后端来处理这些数据,例如 leveldb、pebble、mdbx。
Leveldb
TODO
Pebble
TODO
MDBX
阅读更多关于其特性的信息。此外,boltdb 有一个与其他数据库(如 leveldb)的比较页面,在这里。bolt 中提到的比较要点也适用于 mdbx。
执行层客户端
以太坊虚拟机 (EVM)
以太坊虚拟机 (EVM) 是以太坊世界计算机的核心。它执行完成交易所需的计算,并将结果永久存储在区块链上。本文探讨了 EVM 在以太坊生态系统中的作用及其工作原理。
以太坊状态机
当 EVM 处理交易时,它会改变以太坊的整体状态。从这个角度来看,以太坊可以被视为一个状态机。
在计算机科学中,状态机是一个用于模拟系统行为的抽象概念。状态机可以用 组不同的状态以及驱动状态变化的输入来描述整个系统。
一个常见的例子是自动售货机,这是一个在收到付款后自动分发产品的系统。
我们可以将自动售货机建模为三种不同的状态:空闲、等待选择和分发产品。输入例如投币或选择会触发这些状态之间的转换,如下图所示:
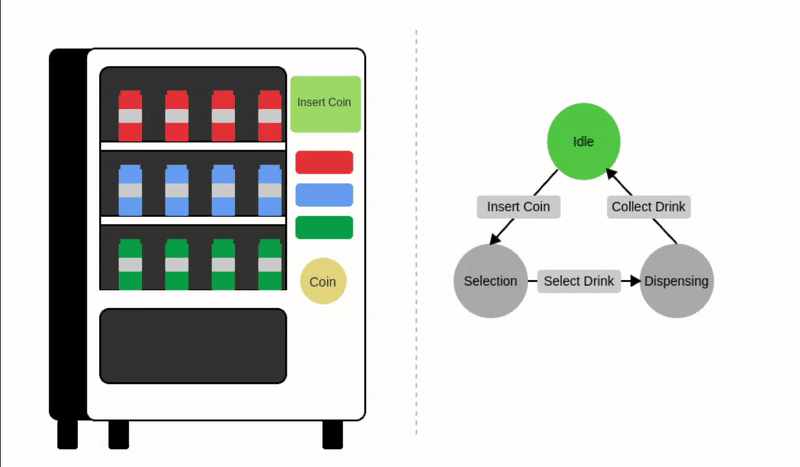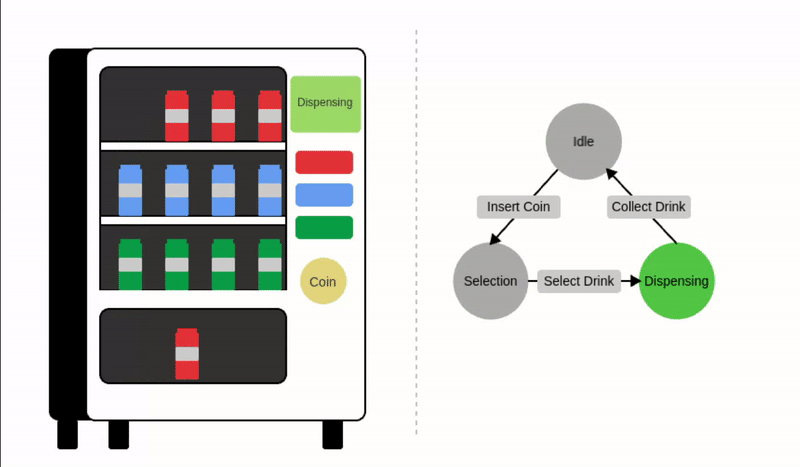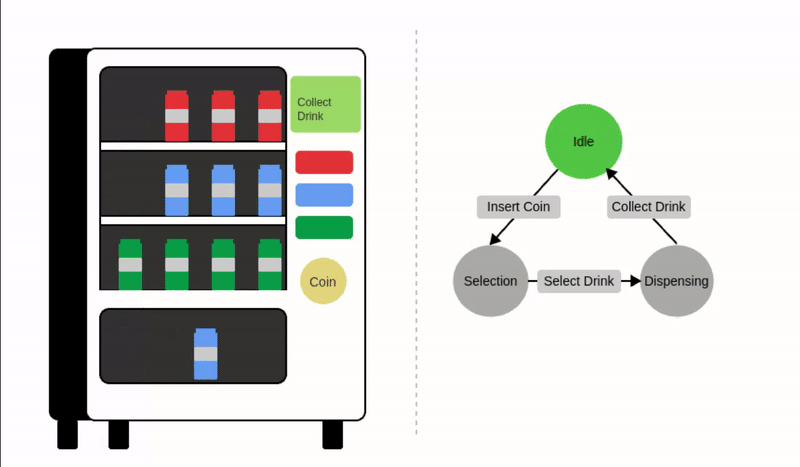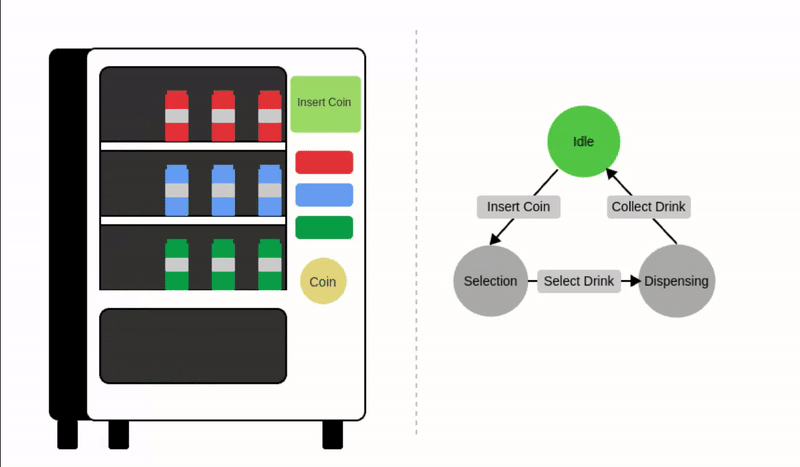
让我们正式定义状态机的组成部分:
- 状态 (): 状态表示系统在某一特定时间点的不同条件或配置。对于自动售货机,可能的状态有:
- 输入 (): 输入是系统环境中的动作、信号或变化。输入触发状态转移函数。对于自动售货机,可能的输入包括:
- 状态转移函数 (): 状态转移函数定义了系统如何基于输入和当前状态从一个状态转移到另一个状态(或回到同一个状态),这决定了系统如何响应输入。
其中 是下一个状态, 是当前状态, 是输入。
状态转移示例:
注意在最后一种情况下,当前状态会回到自身。
作为状态机的以太坊
整个以太坊系统可以被视为一个基于交易的状态机。它接收交易作为输入,并过渡到新的状态。以太坊的当前状态被称为世界状态。
让我们考虑一个简单的以太坊应用程序 —— 一个NFT市场。
在当前世界状态 S3(绿色)中,Alice 拥有一个 NFT。动画显示了一个将 NFT 所有权转移给你的交易(S3 ➡️ S4)。同样,将 NFT 再卖回给 Alice 会将其状态转移到 S5:
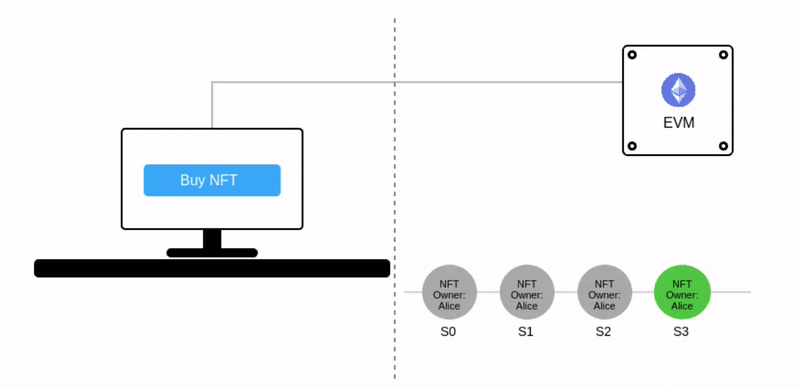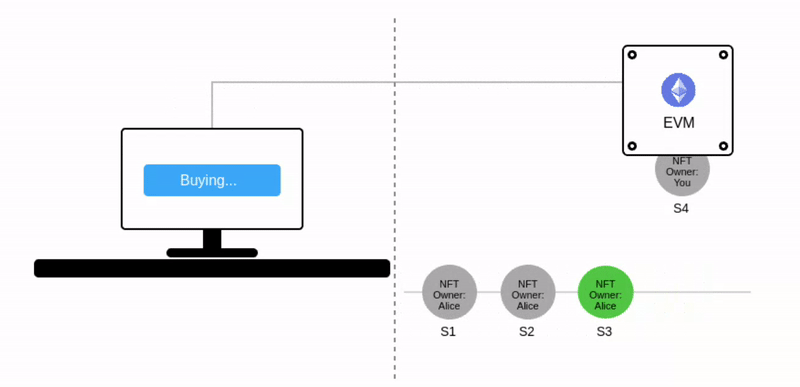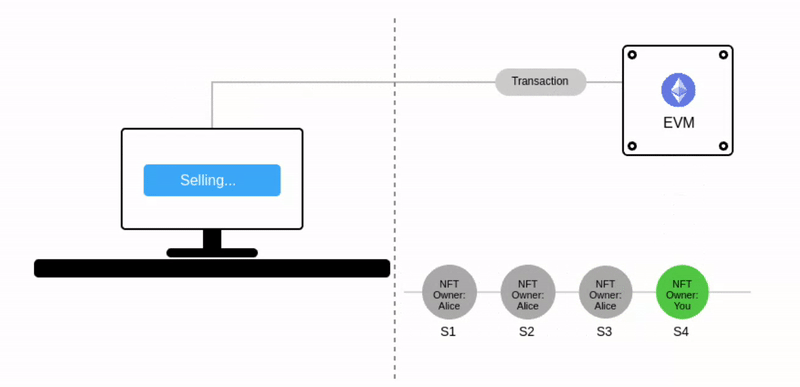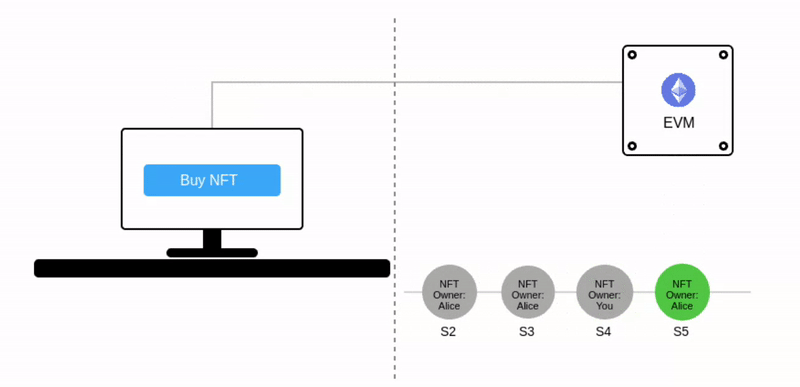
注意当前世界状态会被表示为 跳动的绿色气泡。
在上图中,每笔交易都会形成一个新的状态。而多笔交易会被打包到一个区块中,这个区块产生的最终状态会被添加到之前状态链条中。到这里,相信你已经明白为什么这项技术被称为"区块链"了。
根据状态转移函数的定义,我们得出以下结论:
ℹ️ 注意 EVM 就是以太坊状态机的状态转移函数。它决定了以太坊如何根据输入(交易)和当前状态过渡到新的(世界)状态。
在以太坊中,世界状态本质上是一个 20 字节地址到账户状态的映射。
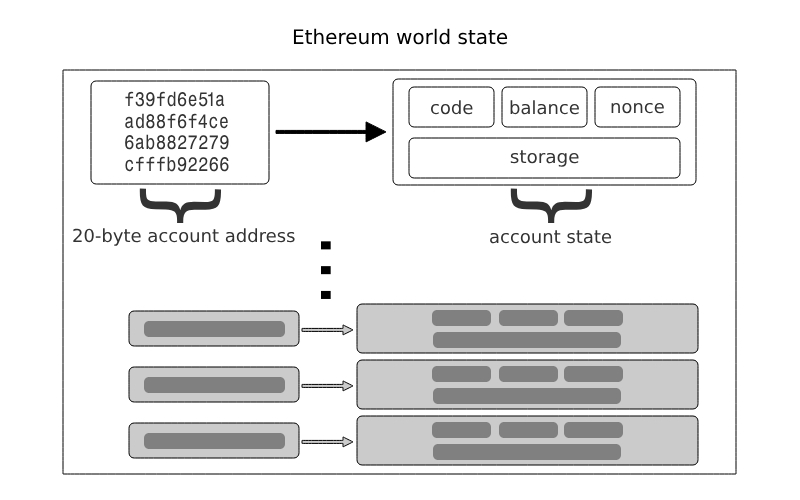
每个账户状态包含各种组件,例如存储、代码、余额等,并与其特定地址相关联。
Ethereum 有两种账户:
- 外部账户: 由与其关联的私钥控制的账户,且其 EVM 代码为空。
- 合约账户: 由与其关联的非空 EVM 代码控制的账户。这段 EVM 代码是合约的一部分,通常被称为 智能合约。
参考 Ethereum 数据结构 了解更多关于世界状态实现的信息。
虚拟机范式
在我们理解了状态机的概念之后,下一个挑战是实现它。
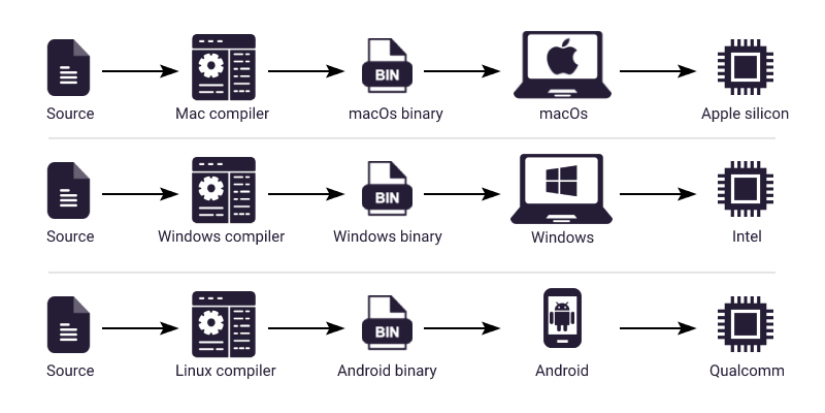
软件需要转换为目标处理器的机器语言(指令集,ISA)才能执行。这种 ISA 因硬件而异(例如,Intel 与 Apple silicon)。现代软件还依赖主机操作系统进行内存管理和其他基本功能。
在由不同硬件和操作系统组成的分散生态系统中确保功能正常是一个主要挑战。传统上,软件必须为每个特定的目标平台编译成原生二进制文件:
为了解决这个挑战,虚拟机采用的解决方案分为两个部分。
首先,讨论面向虚拟机这个抽象层的实现。虚拟机会将源代码被编译成字节码,这是一个表示指令的字节序列。每个字节码都映射到虚拟机执行的特定操作。
第二部分涉及特定平台的虚拟机,它将字节码转换为可执行的原生代码。
这提供了两个关键优势:可移植性(字节码可以在不同平台上运行而无需重新编译)和抽象性(将硬件复杂性与软件分离)。因此,开发人员只需要为单一的虚拟机编写代码:
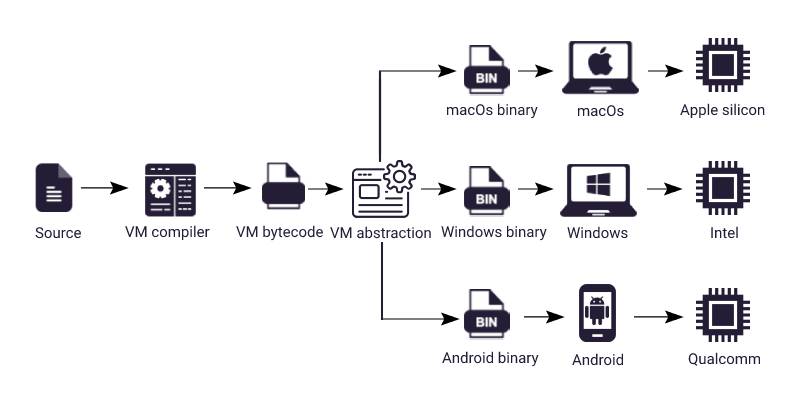
Java 的 JVM 和 Lua 的 LuaVM 是虚拟机的典型例子。它们创建平台无关的字节码,使代码能够在各种系统上运行而无需重新编译。
EVM
虚拟机是计算机架构中的一个抽象概念,而以太坊虚拟机(EVM)是这个抽象的一个具体软件实现。下面描述了 EVM 的架构:
在计算机架构中,字(word)指的是 CPU 一次可以处理的固定大小的数据单元。EVM 的字大小为 32 字节。
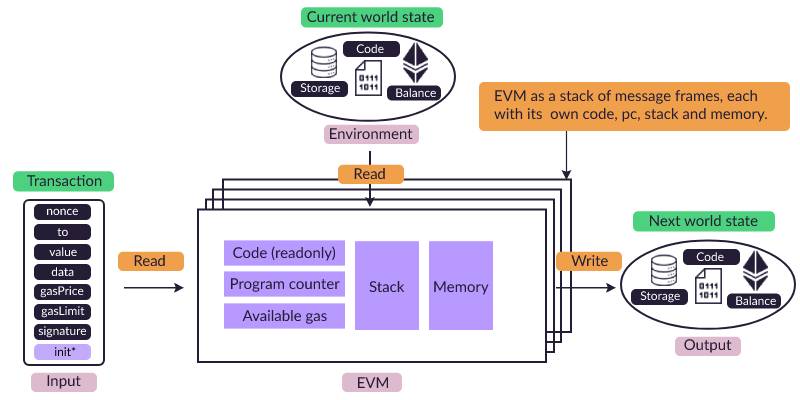
为了清晰起见,上图简化了以太坊状态。实际状态包括消息帧和临时存储等额外元素。
在上述架构图中,可以看到 EVM 正在操作账户实例的存储、代码区和余额。
在实际场景中,EVM 可能会执行涉及多个账户的交易(每个账户都有独立的存储、代码和余额),从而实现以太坊上的复杂交互。
在更好地理解了虚拟机之后,让我们扩展我们的定义:
ℹ️ 注意 EVM 就是以太坊状态机的状态转移函数。它决定了以太坊如何根据输入(交易)和当前状态过渡到新的(世界)状态。它被实现为虚拟机,因此可以在任何平台上运行,不依赖于底层硬件。
EVM bytecode
EVM 字节码是一个程序的表示形式,它是一个字节序列。每个字节码中的字节要么是:
- 一个称为 操作码 的指令,或者
- 一个称为 操作数 的操作码的输入。
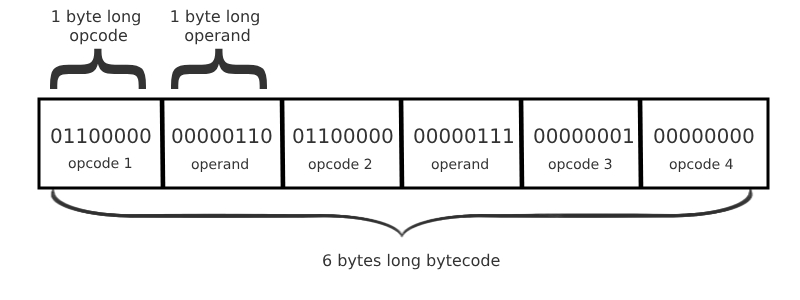
为了简洁起见,EVM 字节码通常用 十六进制 表示:
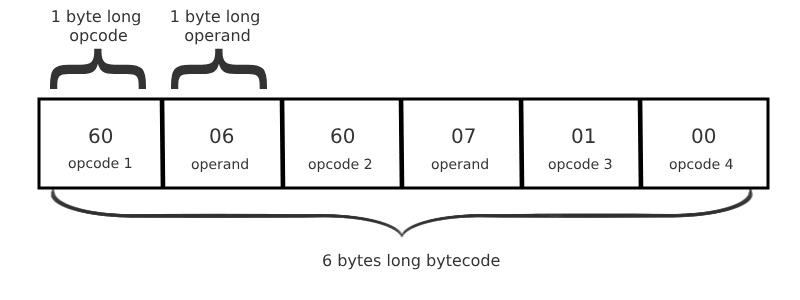
为了进一步增强可读性,操作码有可读的助记符。这种简化的字节码被称为 EVM 汇编,是人类可读的最低层次的 EVM 代码表示形式:
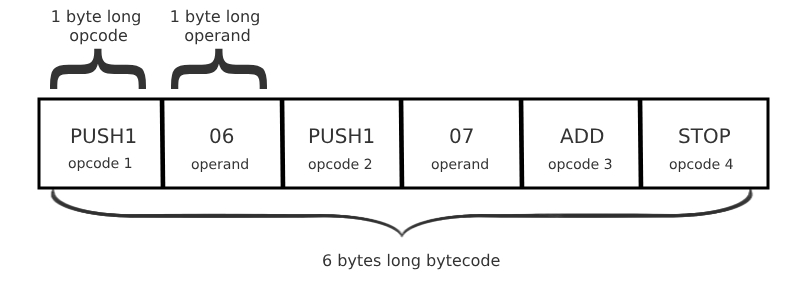
区分操作数和操作码是很直观的。目前,只有 PUSH* 操作码有对应的操作数(这可能会随着 EOF 的实施而改变)。PUSHX 通过 X 定义了操作数的长度(PUSH 操作码后的 X 字节)。
下面列出了本文中使用到的操作码:
| Opcode | Name | Description |
|---|---|---|
| 60 | PUSH1 | Push 1 byte on the stack |
| 01 | ADD | Add the top 2 values of the stack |
| 02 | MUL | Multiply the top 2 values of the stack |
| 39 | CODECOPY | Copy code running in current environment to memory |
| 51 | MLOAD | Load word from memory |
| 52 | MSTORE | Store word to memory |
| 53 | MSTORE8 | Store byte to memory |
| 59 | MSIZE | Get the byte size of the expanded memory |
| 54 | SLOAD | Load word from storage |
| 55 | SSTORE | Store word to storage |
| 56 | JUMP | Alter the program counter |
| 5B | JUMPDEST | Mark destination for jumps |
| f3 | RETURN | Halt execution returning output data |
请参考 Yellow Paper 的附录 H 获取完整列表。
Ethereum 客户端(如 geth)实现了 EVM 规范。这确保了所有节点在交易如何改变系统状态方面达成一致,从而在网络中创建了一个统一的执行环境。
我们已经讨论了EVM 是什么,现在让我们探索它是如何工作的。
栈(Stack)
栈是一种简单的数据结构,具有两个操作:PUSH 和 POP。Push 将一个项添加到栈顶,而 pop 则移除栈顶的项。栈遵循后进先出(LIFO)原则——最后添加的元素是第一个被移除的。如果尝试从空栈中弹出,将发生栈下溢错误。
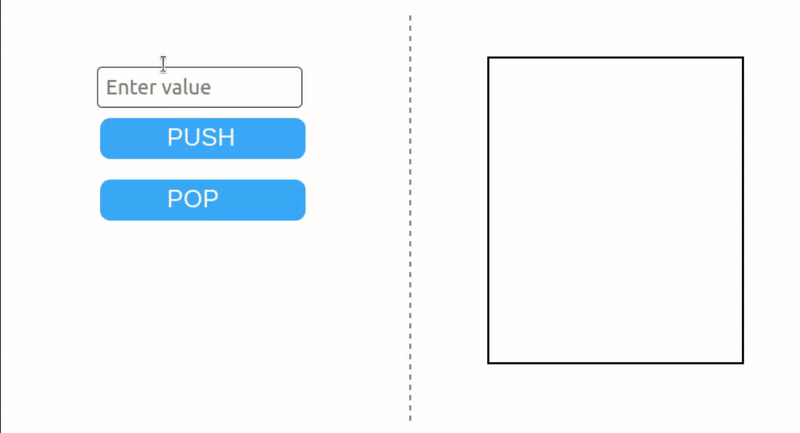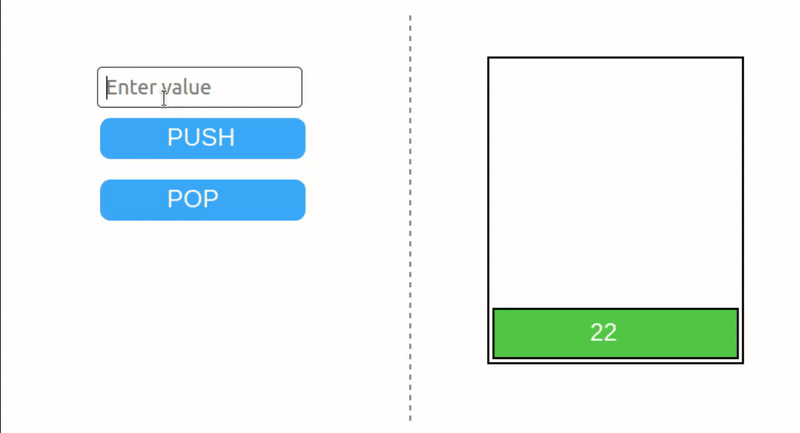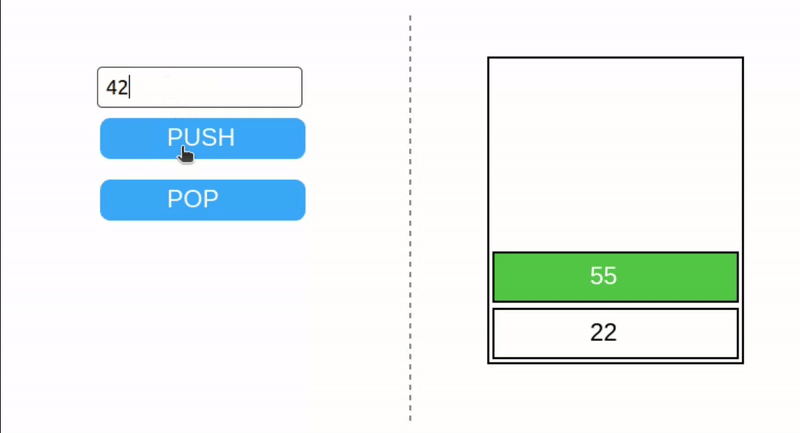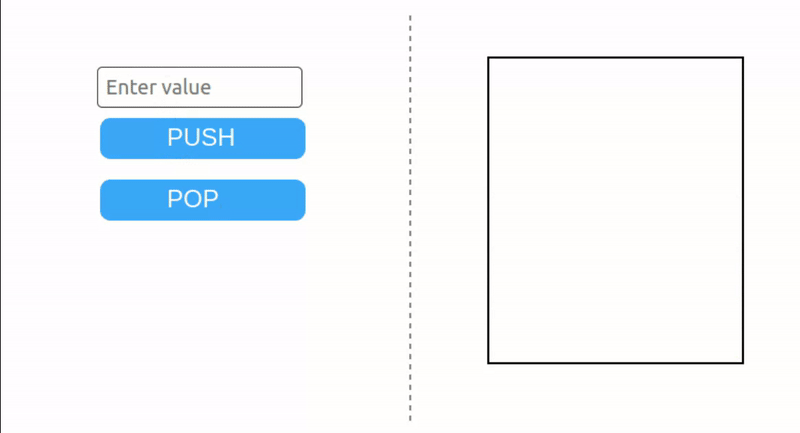
EVM 栈的最大大小为 1024 项。
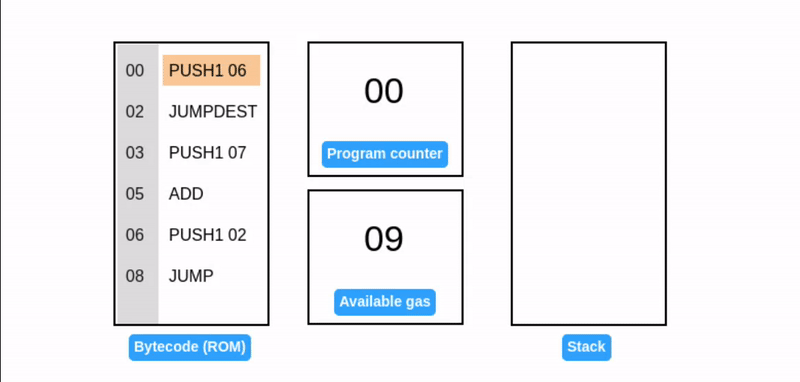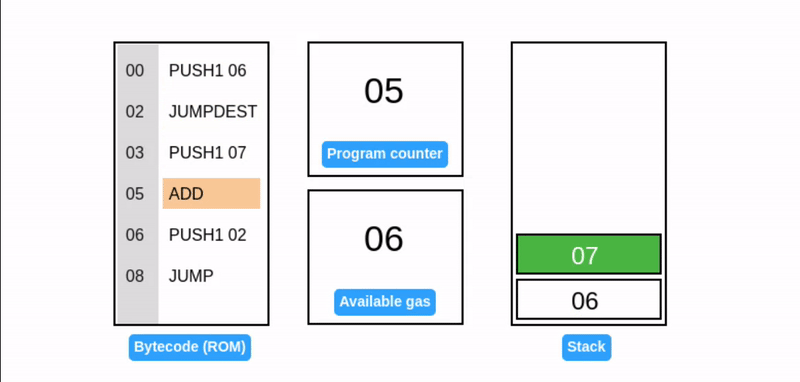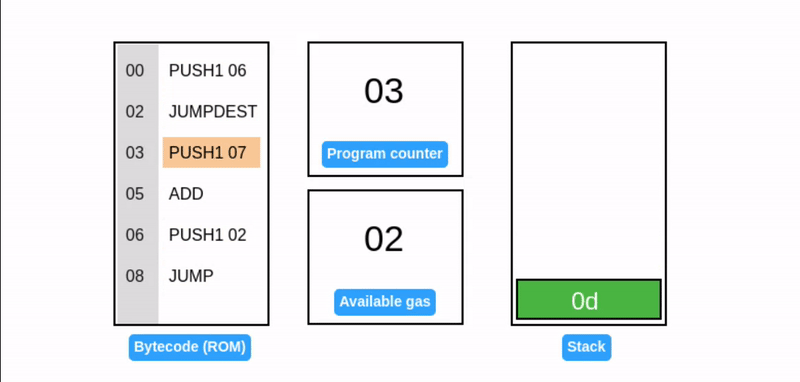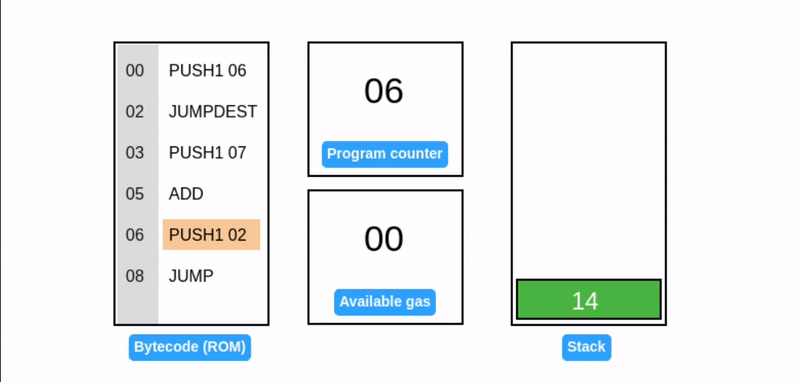
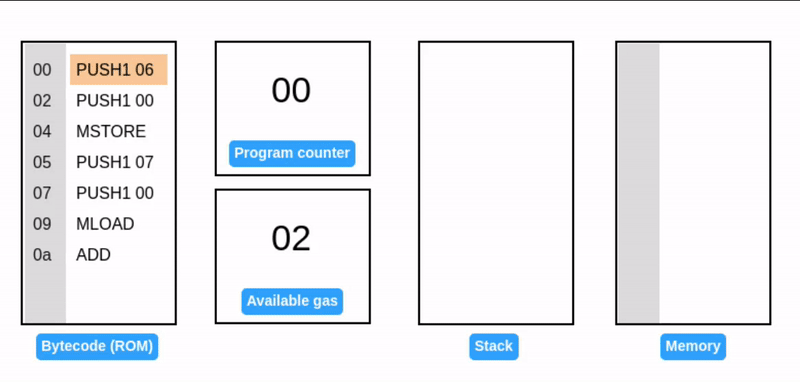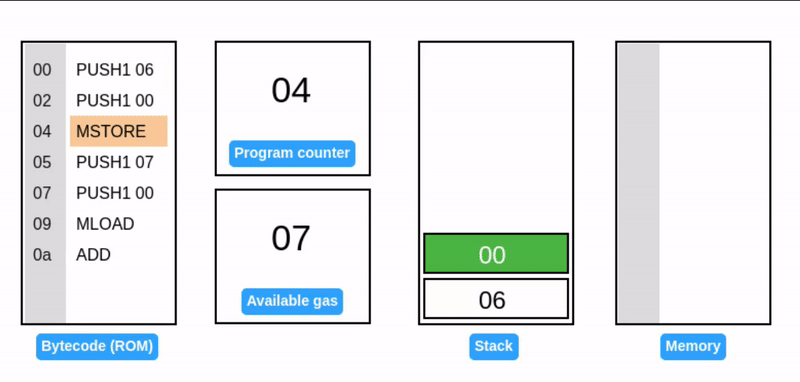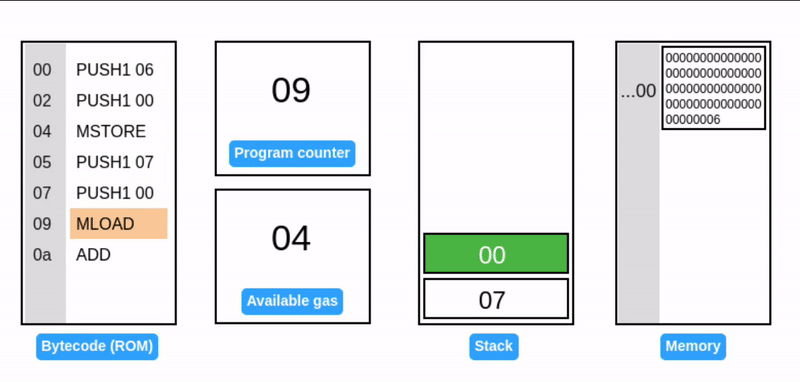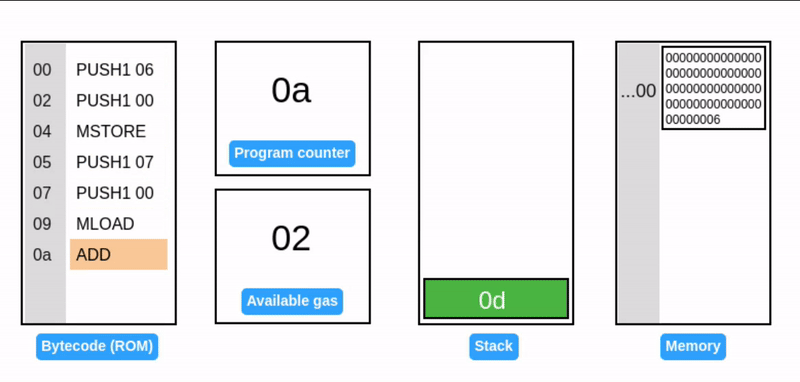
在字节码执行期间,EVM 栈作为临时存储使用:操作码从栈顶消耗数据,并将其结果推回栈顶(见下面的 ADD 操作码)。考虑一个简单的加法程序:
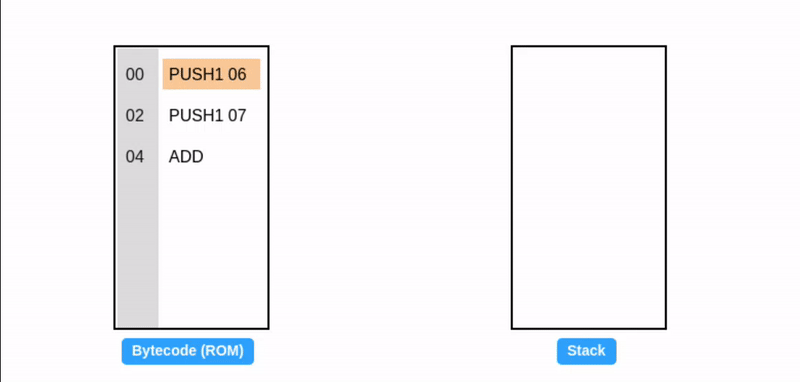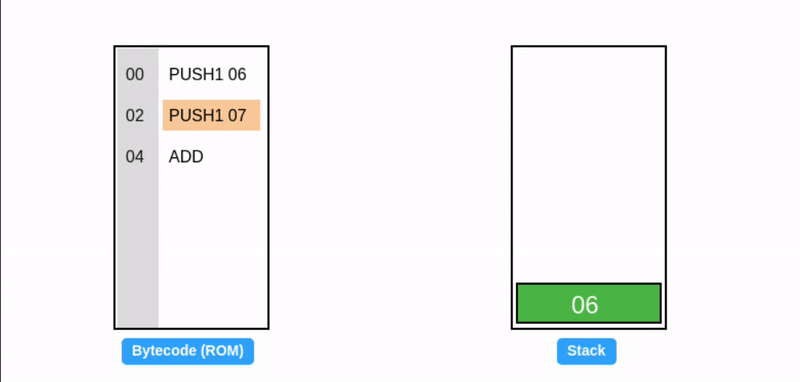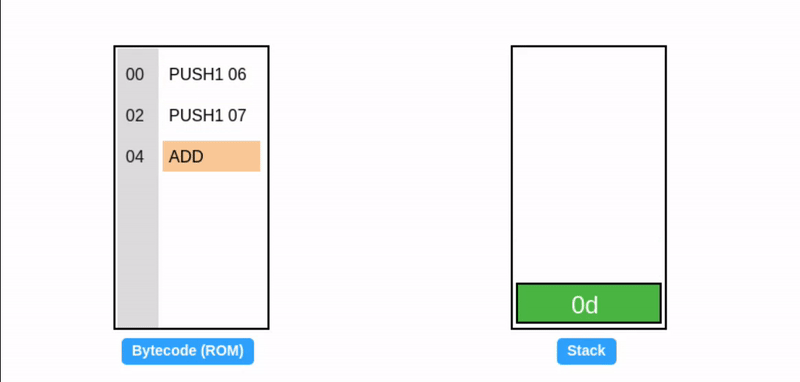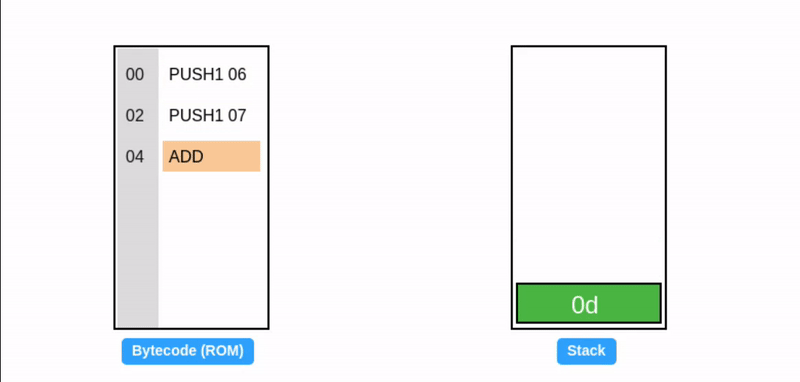
提示:所有值都是十六进制的,所以 0x06 + 0x07 = 0x0d (十进制: 13)。
让我们花点时间庆祝一下我们编写的第一行 EVM 汇编代码 🎉。
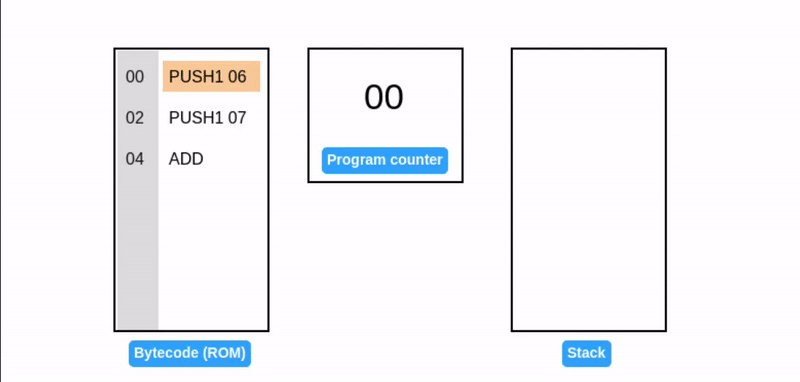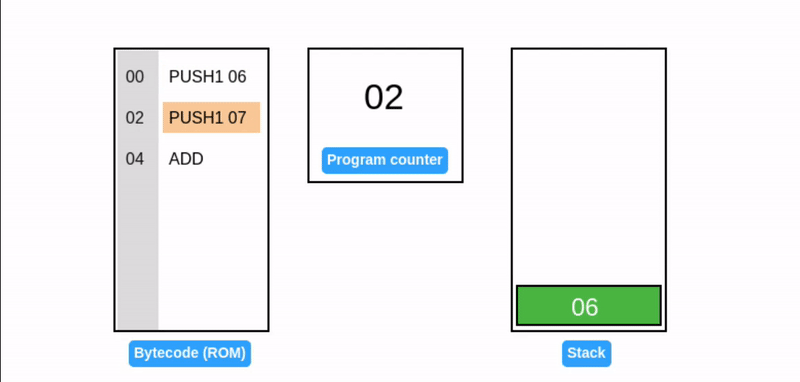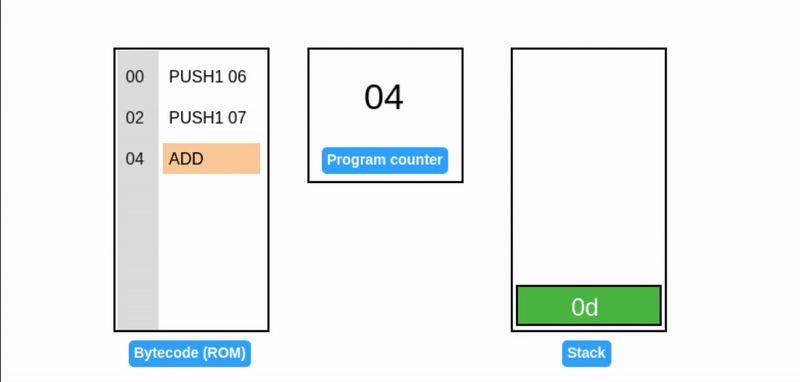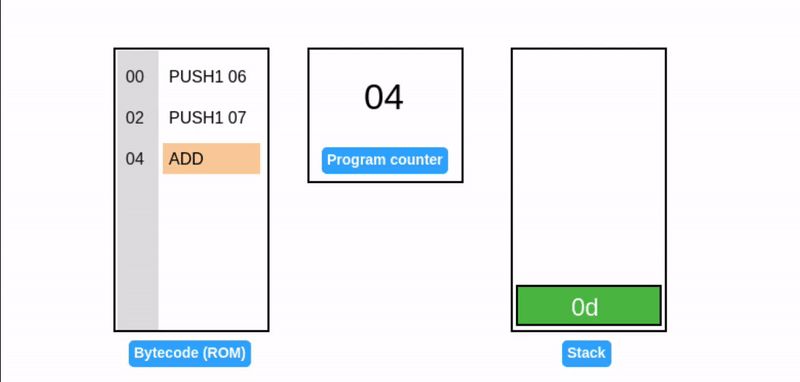
程序计数器(Program counter)
在上述示例中,汇编代码左侧的值表示字节码中每个操作码的字节偏移量(从 0 开始):
| 字节码 | 汇编指令 | 指令长度(字节) | 字节偏移量(十六进制) |
|---|---|---|---|
| 60 06 | PUSH1 06 | 2 | 00 |
| 60 07 | PUSH1 07 | 2 | 02 |
| 01 | ADD | 1 | 04 |
EVM 用程序计数器存储下一个要执行的操作码的字节偏移量(高亮显示)。
JUMP 操作码通过直接设置程序计数器,启用动态控制流从而允许灵活的程序执行路径并使 EVM 具有 图灵完备性。
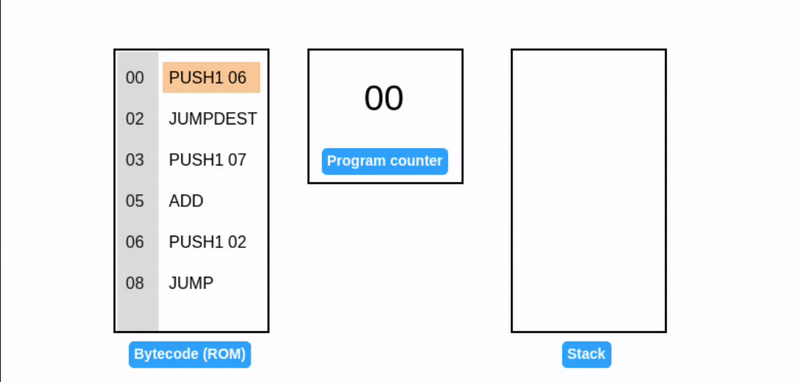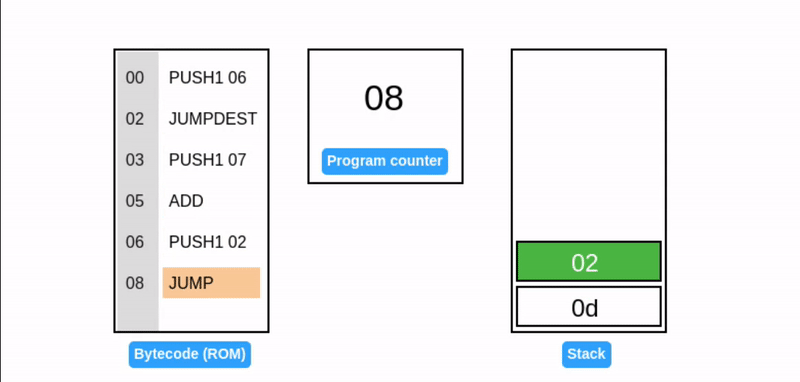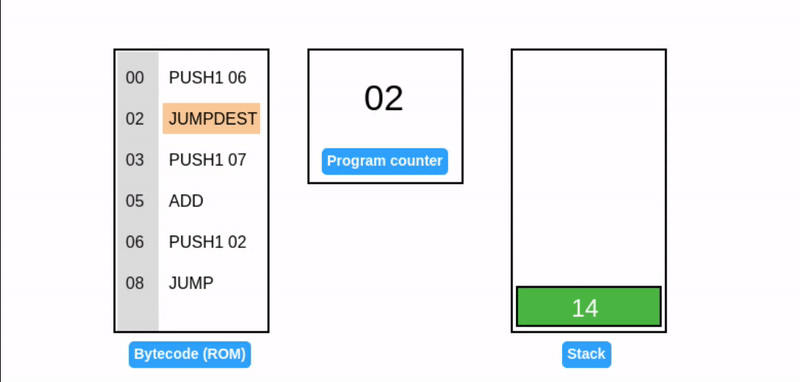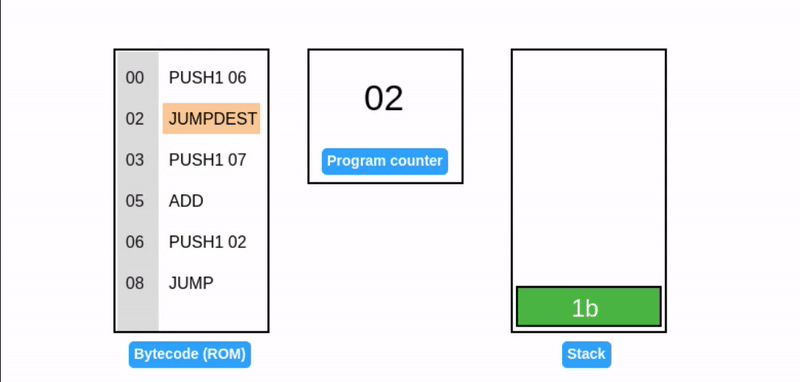
这段代码正在执行一个死循环,并不断地往栈顶添加元素 7。它引入了两个新操作码:
- JUMP: 将程序计数器设置为栈顶值(在我们的例子中是 02),确定下一个要执行的指令。
- JUMPDEST: 标记跳转操作的目的地,确保预期的目的地。
高级别语言(如 Solidity)利用
JUMP和JUMPDEST实现诸如条件、循环和内部函数调用等语句。
汽油费(Gas)
我们的小程序可能看起来无害。但是其中的无限循环对 EVM构成了重大威胁:它们可以耗尽资源,可能导致网络 拒绝服务攻击。
EVM 的 gas 机制通过充当计算使用资源的货币来应对这种威胁。gas 费基于使用的硬件资源(如存储容量或计算能力)来计算。交易通过以太坊代币支付 gas 费以使用 EVM,如果它们在完成之前耗尽 gas 费(如无限循环),EVM 会停止该交易继续执行以防止资源耗尽。
这保护了网络免受资源密集型或恶意攻击的影响。由于 gas 费限制了计算步骤的数量,EVM 被认为是准图灵完备的。
在我们的示例中,假设每个操作码消耗 1 单位的 gas 以简化计算,但实际 gas 成本会根据操作码的复杂性而变化。不过核心理念是一致的。
请参考 Yellow Paper 的附录 G 获取具体的 gas 费。
内存(Memory)
EVM 内存是一个字节数组,大小为 (或 实际无限)字节。所有内存位置会初始化为零。

与用来存储每个指令所需操作数据的栈不同,内存存储与整个程序相关的临时数据。
写入内存
MSTORE 从栈中获取两个值:一个偏移量和一个 32 字节的值。然后,它将该值写入指定偏移量的内存中。
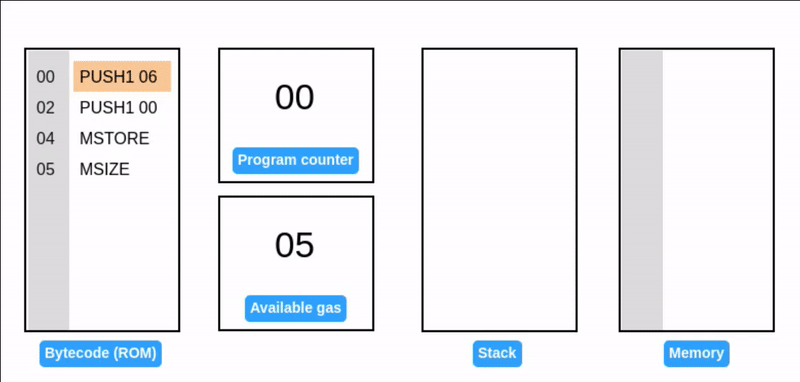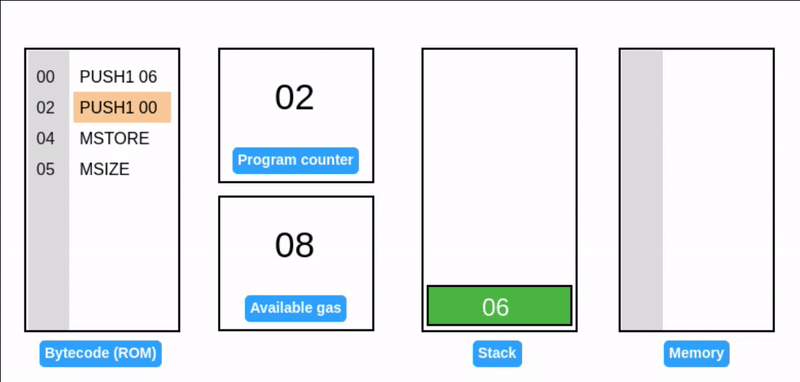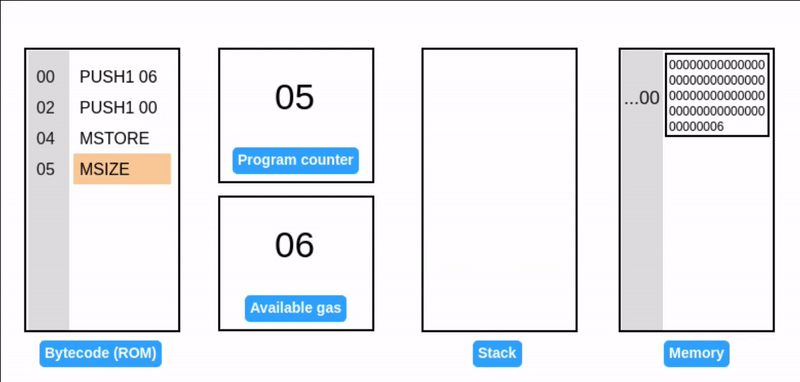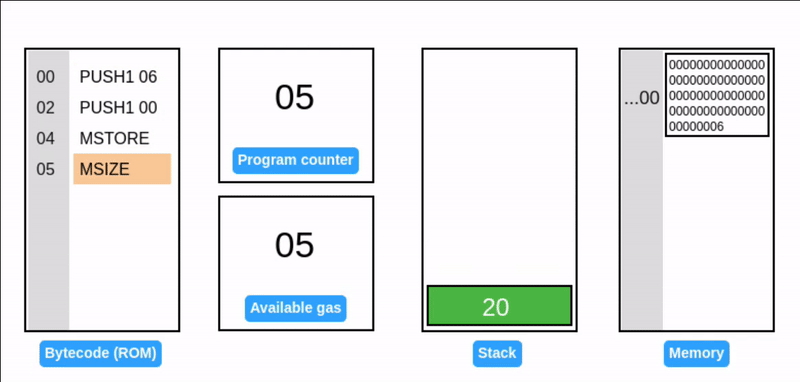
MSIZE 报告当前使用的内存大小(以字节为单位)并压入栈中。
MSTORE8 与 MSTORE 类似,但只写入 1 字节。
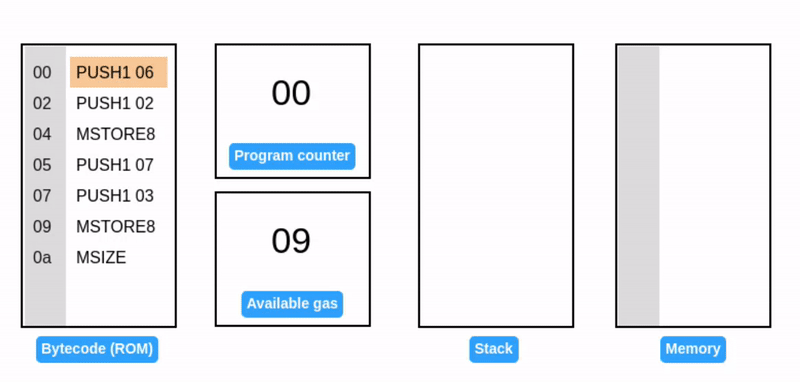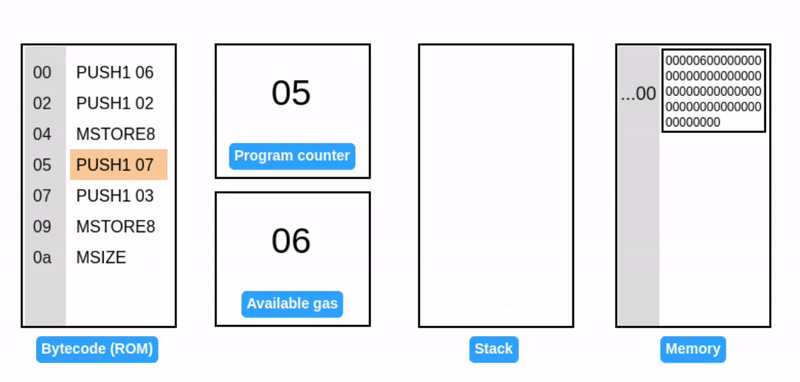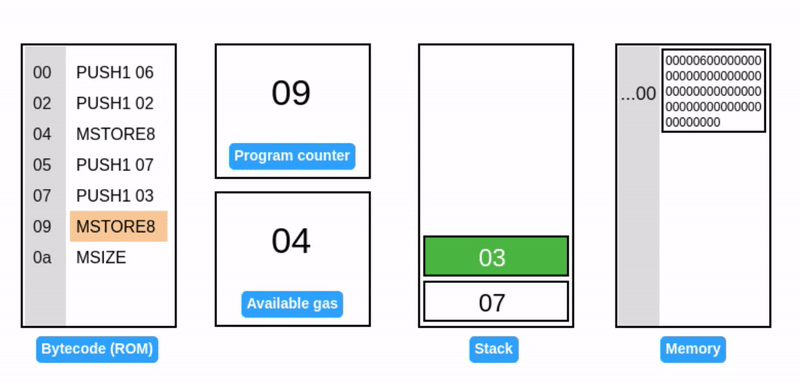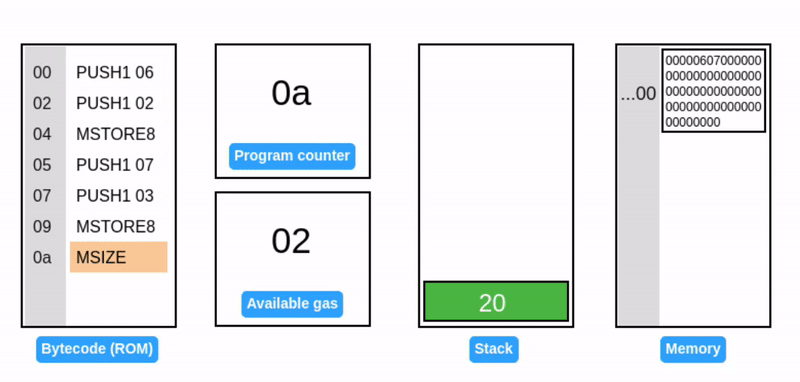
注意:当写入 07 到内存时,现有的值(06)保持不变。07 会被写入相邻的字节。
当前占用的内存大小仍然是 1 个字。
内存扩展 (Memory expansion)
在 EVM 中,内存是按 1 个字(32 字节)的倍数动态分配的。EVM 也会基于扩展的页数收取 gas 费。
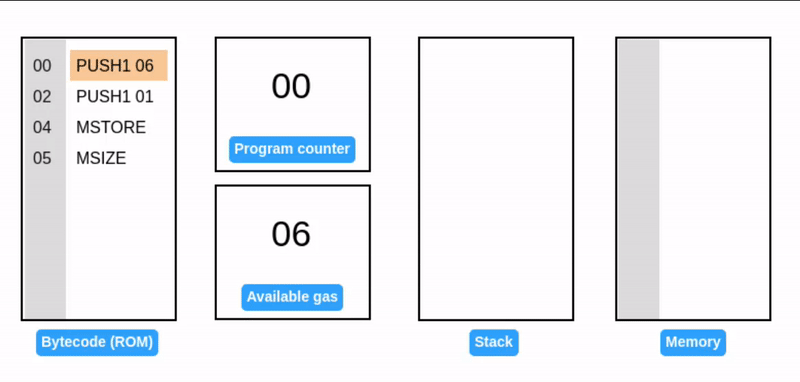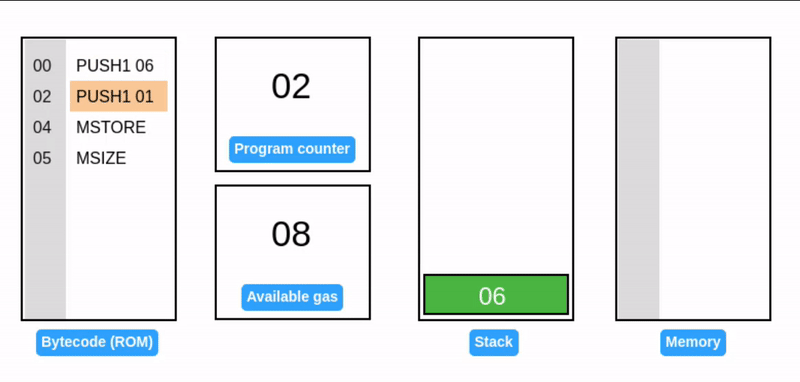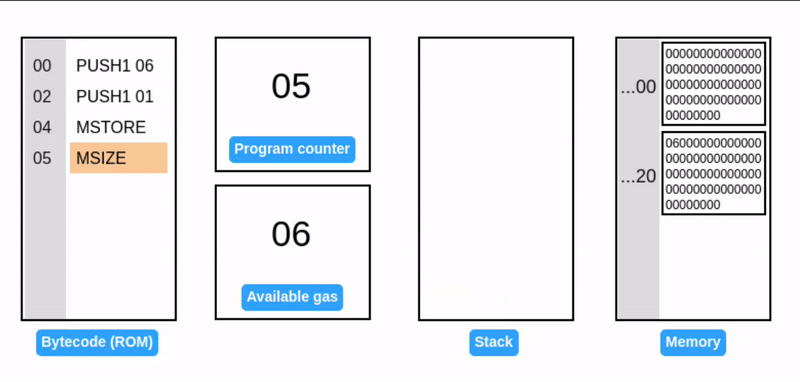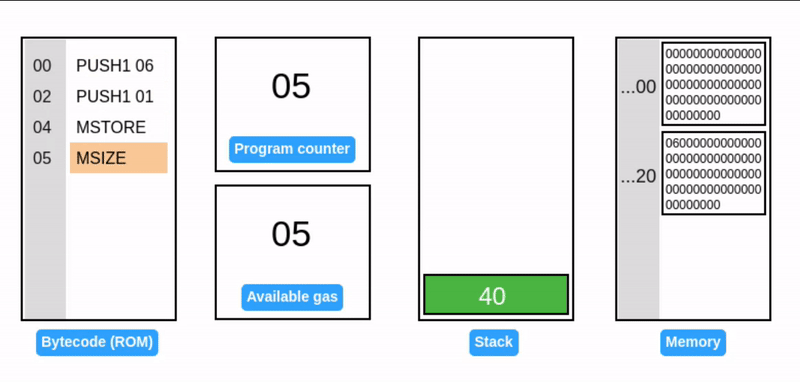
在一个字节偏移量的位置写入一个字,会导致溢出初始内存页,触发内存扩展到 2 个字(64 字节或 0x40)。
读取内存 (Reading from memory)
MLOAD 指令从内存中读取一个值并压入栈中。
EVM 没有直接等价的 MSTORE8 用于读取。必须使用 MLOAD 读取整个字,然后使用 掩码 提取所需的字节。
EVM 内存被显示为 32 字节的块,以说明内存扩展的工作原理。实际上,它是一个连续的字节序列,没有任何固有的分隔或块。
Storage
Storage 被设计为一个以字为地址的字数组。与 Memory 不同,Storage 与以太坊账户相关联,并作为世界状态的一部分在交易之间持久保存。
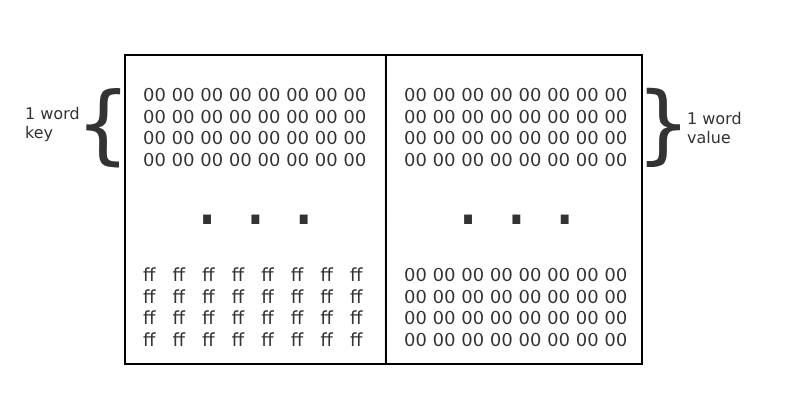
Storage 只能通过其关联账户的代码来访问。外部账户没有代码,因此无法访问自己的 Storage。
Writing to storage
SSTORE 从栈中获取两个值:一个存储槽位和一个 32 字节的值。然后它将该值写入账户的 Storage 中。
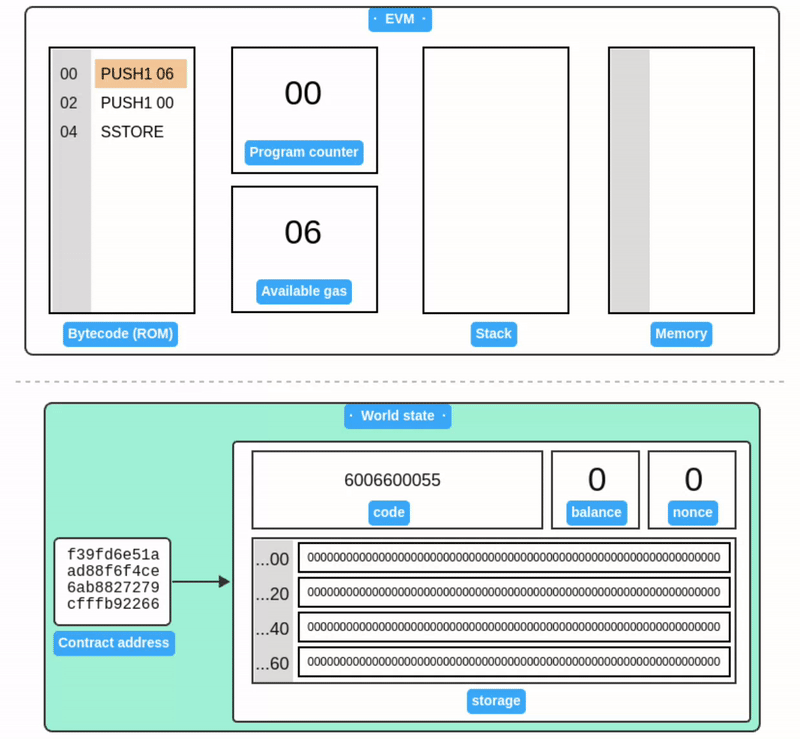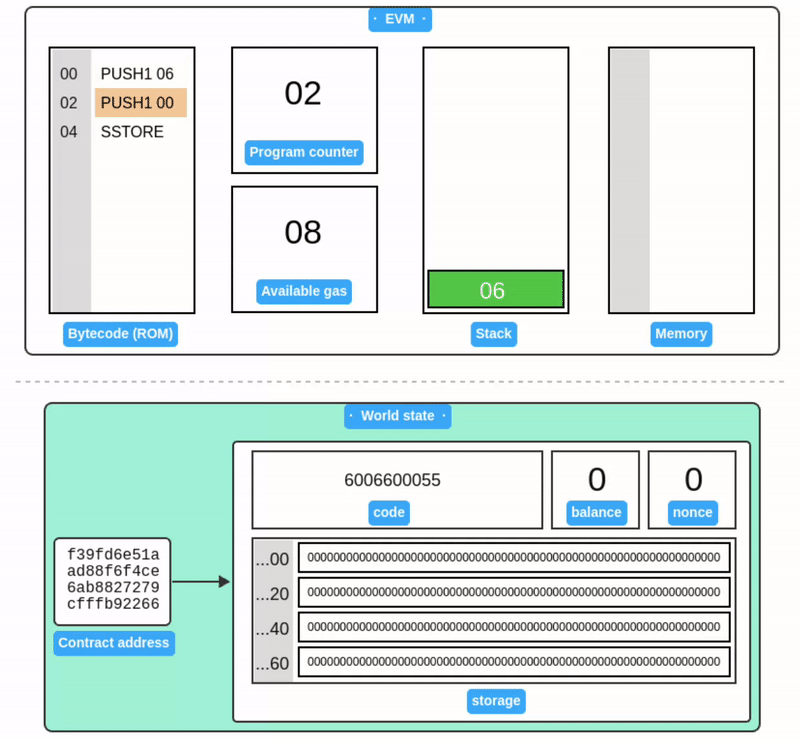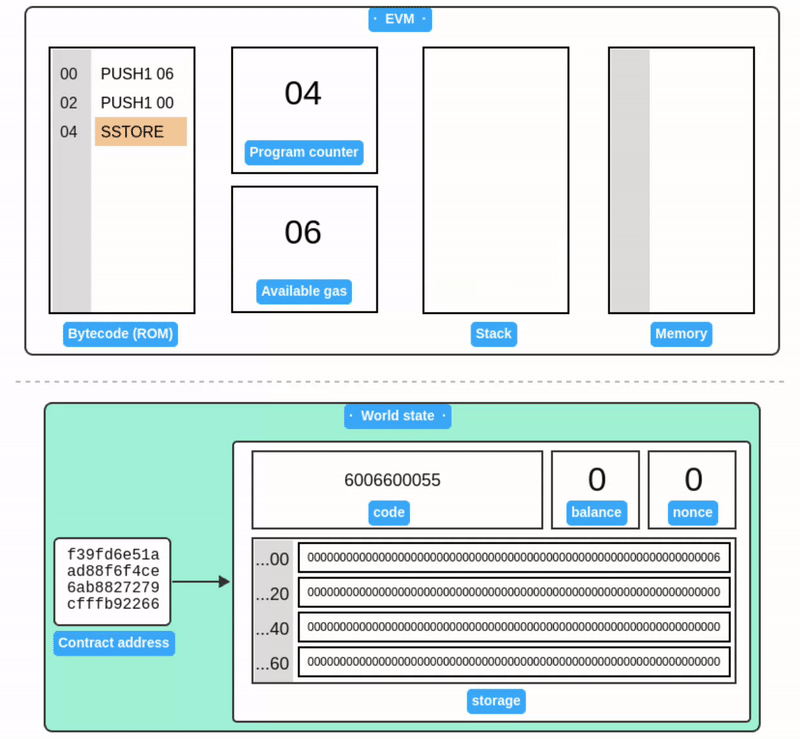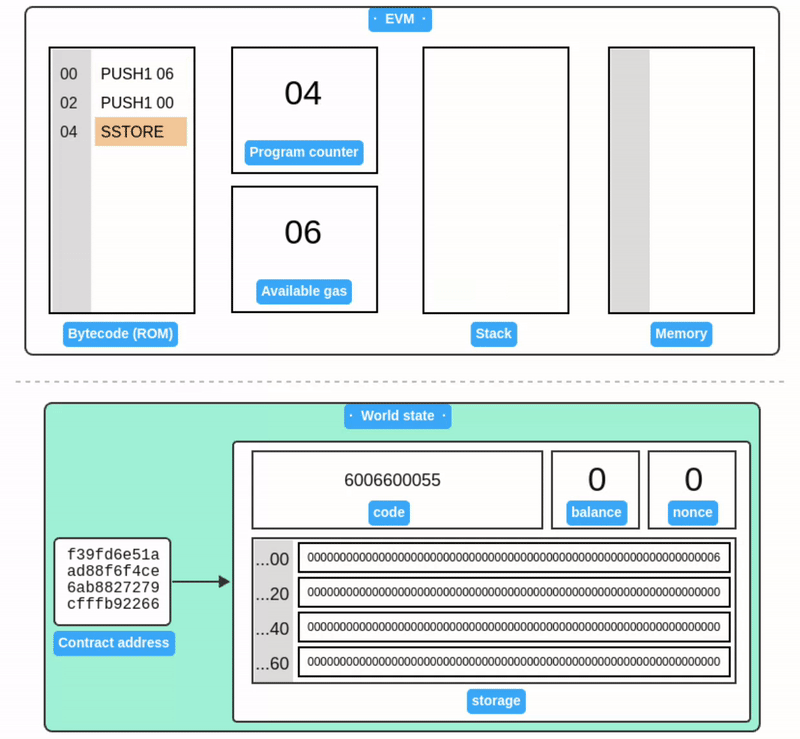
在此之前,我们一直在关注合约账户的字节码执行过程。现在当我们看到账户和世界状态时,就能发现它们与 EVM 内部运行的代码是完全对应的。
再次强调,Storage 不是 EVM 本身的一部分,而是属于当前执行的合约账户。
上面的例子只展示了账户 Storage 的一小部分。与内存一样,Storage 中的所有值初始都被定义为零。
读取存储 (Reading from storage)
SLOAD 从栈中获取存储槽位,并将其值加载回栈中。
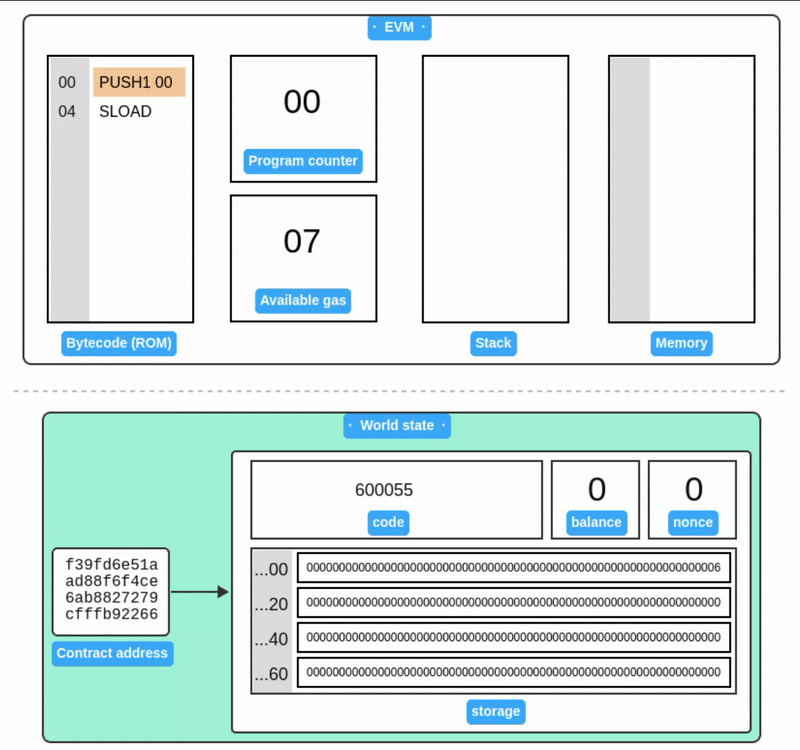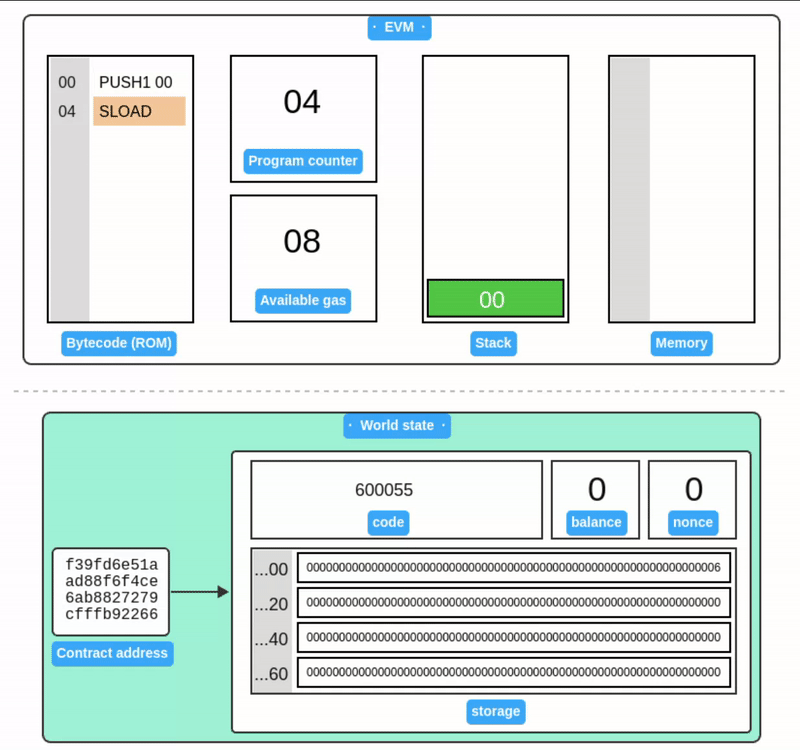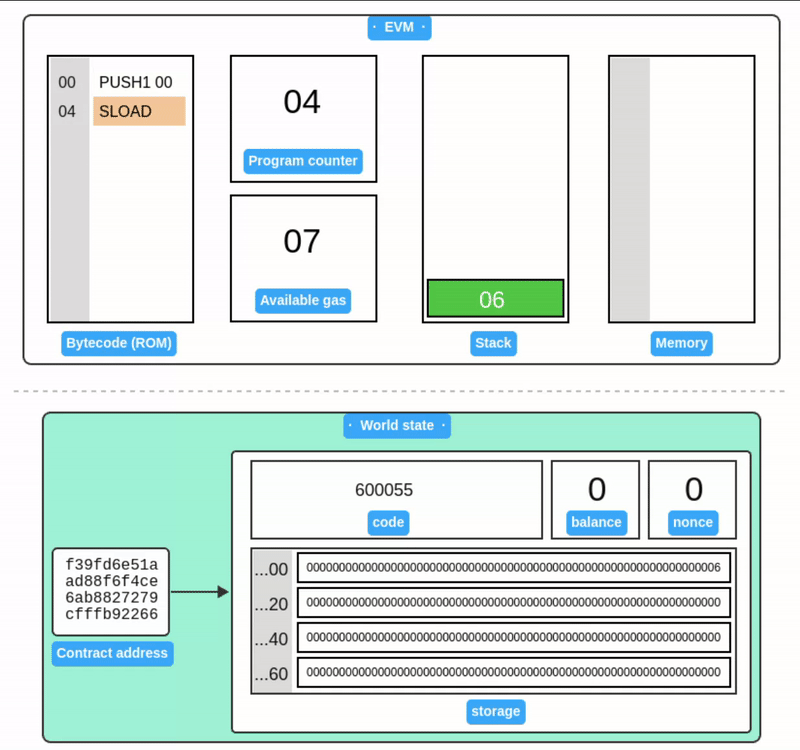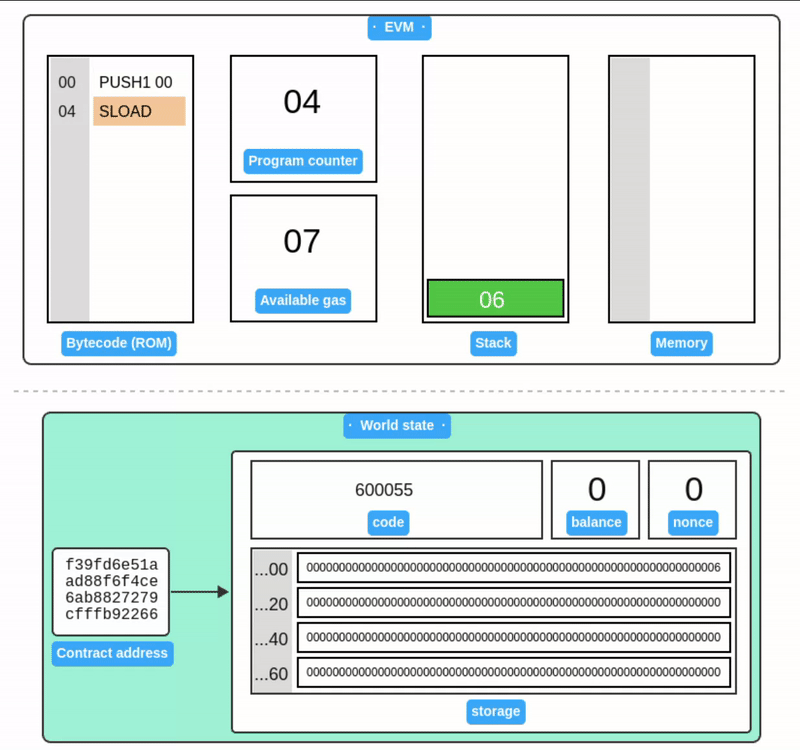
注意存储值在示例之间保持不变,这展示了它在世界状态中的持久性。由于世界状态需要在所有节点间复制,存储操作的 gas 费用很高。
ℹ️ 注意 查看 transaction 维基页面以了解 EVM 的实际运行。
Wrapping up
除非性能优化至关重要,否则开发人员很少直接编写 EVM 汇编代码。相反,大多数开发人员使用像 Solidity 这样的高级语言,然后将其编译成字节码。
以太坊是一个持续发展的协议,虽然我们讨论的基础知识将在很大程度上保持不变,但建议关注 以太坊改进提案(EIPs) 和 网络升级,以了解以太坊生态系统的最新发展。
以太坊虚拟机升级(EVM upgrades)
虽然以太坊协议在每次升级中都会经历许多变化,但 EVM 的变化相对较小。因为 EVM 的重大变更可能会破坏合约和语言的兼容性,需要维护多个版本的 EVM,这会带来大量的复杂性开销。EVM 本身仍然会进行一些不破坏其逻辑的升级,比如新的操作码或对现有操作码的修改。一些例子是像 1153、4788、5000、5656 和 6780 这样的 EIP。除了最后一个特别有趣的 EIP(它在不破坏兼容性的情况下中和了 SELFDESTRUCT 操作码)之外,这些都在提议添加新的操作码。另一个标志着重大变革的重要 EVM 升级是 EOF。它为字节码创建了一种 EVM 可以更容易理解和处理的格式,涵盖了各种 EIP,并且已经讨论和完善了相当长的时间。
资源
状态机和计算理论
- 📝 Mark Shead, "Understanding State Machines." • archived
- 🎥 Prof. Harry Porter, "Theory of computation."
- 📘 Michael Sipser, "Introduction to the Theory of Computation."
- 🎥 Shimon Schocken et al., "Build a Modern Computer from First Principles: From Nand to Tetris."
EVM 学习资源
下面根据不同的学习阶段和目标汇总了一些 EVM 相关的学习资料。
EVM 基础
- 🎥 Whiteboard Crypto, "EVM: An animated non-technical introduction."
- 📝 Vasa, Getting Deep Into EVM: How Ethereum Works Backstage
- 📝 Zaryab Afser, The ABCs of Ethereum Virtual Machine
- 📝 Preethi, EVM Tweet Thread
- 📝 Decipher Club, EVM learning resources based on your level of expertise
理解 EVM 架构和核心组件
- 📝 Gavin Wood, "Ethereum Yellow Paper."
- 📝 Ethereum Book, Chapter 13, Ethereum Book
- 📘 Andreas M. Antonopoulos & Gavin Wood, "Mastering Ethereum."
- 🎥 Jordan McKinney, "Ethereum Explained: The EVM."
- 📝 LeftAsExercise, "Smart contracts and the Ethereum virtual machine." • archived
- 📝 Femboy Capital, "A Playdate with the EVM." • archived
- 🎥 Alex, EVM - Some Assembly Required
EVM 深入探讨
- 📝 Takenobu Tani, EVM illustrated
- 📝 Shafu, "EVM from scratch."
- 📝 NOXX, "3 part series: EVM Deep Dives - The Path to Shadowy Super Coder." • archived
- 📝 OpenZeppelin, "6 part series: Deconstructing a Solidity." • archived
- 📝 TrustLook, "Understand EVM bytecode." • archived
- 📝 Degatchi, "A Low-Level Guide To Solidity's Storage Management." • archived
- 📝 Zaryab Afser, "Journey of smart contracts from Solidity to Bytecode"
- 🎥 Ethereum Engineering Group, EVM: From Solidity to byte code, memory and storage
- 📝 Trust Chain, 7 part series about how Solidity uses EVM under the hood.
EVM 工具和习题
- 🧮 smlXL, "evm.codes: Opcode reference and interactive playground."
- 🧮 smlXL, "evm.storage: Interactive storage explorer."
- 🧮 Ethervm, Low level reference for EVM opcodes
- 🎥 Austin Griffith, "ETH.BUILD."
- 💻 Franco Victorio, "EVM puzzles."
- 💻 Dalton Sweeney, "More EVM puzzles."
- 💻 Zaryab Afser, "Decipher EVM puzzles."
EVM 实现
- 💻 Solidity: Brock Elmore, "solvm: EVM implemented in solidity."
- 💻 Go: Geth
- 💻 C++: EVMONE
- 💻 Python: py-evm
- 💻 Rust: revm
- 💻 Js/CSS: Riley, "The Ethereum Virtual Machine."
EVM 支持的编程语言
预编译合约
预编译合约是一组特殊账户,每个账户都包含一个内置函数,并具有确定的 gas 成本,这些函数通常与复杂的加密计算相关。目前,它们定义在地址范围 0x01 到 0x0a 之间
与普通的合约账户不同,预编译合约是以太坊协议的一部分,由执行客户端实现。这导致一个有趣的特性:在 EVM 中,它们的 EXTCODESIZE 值为 0, 然而,它们在执行时表现得像带有代码的合约账户
根据 EIP-2929 的定义,预编译合约被包括在交易的初始“已访问地址”中,以节省gas成本
预编译合约与操作码的比较
预编译合约和操作码的目标都是执行任意计算。在两者之间做出选择时,需要考虑以下因素:
- 有限的操作码空间: EVM 的 1 字节操作码空间本质上是有限的(256 个操作码,范围 0x00 到 0xFF), 这需要对必要操作进行谨慎分配
- 效率: 预编译合约本质上在 EVM 外执行,从而实现了复杂加密计算的高效实现,这些计算支持许多跨链交互
引用 Vitalik 在"以太坊协议的前世今生"中的描述:
"第二个是‘预编译合约’的概念,它解决了在 EVM 中使用复杂加密计算而无需处理 EVM 开销的问题。 我们还探讨过更具野心的想法,即‘原生合约’,即如果矿工能够为某些合约提供优化实现,他们可以“投票”降低这些合约的 gas 价格,这样大多数矿工能够更快执行的合约自然会拥有更低的 gas 价格;然而,这些想法最终被否决了,因为我们无法设计出一种加密经济学上安全的方式来实现这一点。攻击者总是可以创建一个执行某些带有后门的加密操作的合约,然后将后门分发给自己和朋友,让他们能够更快地执行此合约,再投票降低 gas 价格,并利用此方法对网络发动拒绝服务(DoS)攻击。相较之下,我们选择了一种目标较小的方式:在协议中简单地指定少量预编译合约,用于诸如哈希和签名方案等常见操作”
预编译合约列表
| 地址 | 名称 | 描述 | 引入版本 |
|---|---|---|---|
| 0x01 | ECRECOVER | 椭圆曲线公钥恢复 | Frontier |
| 0x02 | SHA2-256 | SHA2 256 位哈希算法 | Frontier |
| 0x03 | RIPEMD-160 | RIPEMD 160 位哈希算法 | Frontier |
| 0x04 | IDENTITY | 身份函数 | Frontier |
| 0x05 | MODEXP | 任意精度模幂运算 | Byzantium (EIP-198) |
| 0x06 | ECADD | 椭圆曲线加法 | Byzantium (EIP-196) |
| 0x07 | ECMUL | 椭圆曲线标量乘法 | Byzantium (EIP-196) |
| 0x08 | ECPAIRING | 椭圆曲线配对检查 | Byzantium (EIP-197) |
| 0x09 | BLAKE2 | BLAKE2 压缩函数 | Istanbul (EIP-152) |
| 0x0a | KZG POINT EVAL | 验证 KZG 证明 | Cancun (EIP-4844) |
工作原理
预编译合约的优势在于其接口设计,这与外部智能合约调用相同, 从开发者的角度来看,使用预编译合约与调用外部合约没有区别
预编译合约的 gas 成本直接与输入数据相关 — 固定输入对应固定成本。开发者通过参考实现和基准测试来确定这些成本。基准测试通常在特定硬件上测量执行时间,而某些合约(如 MODEXP)则直接以每秒的 gas 使用量来定义消耗, 这种严谨的方法旨在通过确保资源分配的可预测性来阻止拒绝服务(DoS)攻击
在底层实现中,客户端使用优化的库来执行预编译合约。虽然这提高了效率,但也引入了潜在的安全风险。如果这些库中存在漏洞,可能会破坏整个协议层,为了降低风险,严格的测试是必不可少的(e.g: MODEXP test specs)
为了防止漏洞,预编译合约的设计避免了嵌套调用
调用预编译
与合约账户类似,预编译合约可以使用 CALL 系列操作码进行调用
以下是一个使用 SHA-256 预编译合约来哈希字符串 "Hello" 的汇编代码示例:
PUSH5 0x48656C6C6F // Push "Hello" in UTF-8
PUSH1 0
MSTORE
PUSH1 0x20 // Output size
PUSH1 0x20 // Input size
PUSH1 5 // Input offset
PUSH1 0x1B // Address of SHA-256 precompile
PUSH1 2 // Gas limit
PUSH4 0xFFFFFFFF // Gas price
STATICCALL // Call the precompile
POP // Pop result from stack
PUSH1 0x20
MLOAD // Load the result from memory
生成以下哈希值:
185f8db32271fe25f561a6fc938b2e264306ec304eda518007d1764826381969
在 EVM playground 中可以尝试以上试验
关于汇编代码是如何工作的, 可以参考: EVM
已提案的预编译合约
EIP 提案可以通过硬分叉引入新的预编译合约,然而,由于测试和维护负担的增加,人们通常对增加新的预编译合约持保留态度。
一种建议的方法是先在 Layer 2 解决方案上对预编译合约进行原型设计,只有在证明其稳定性和广泛采用之后,才将其集成到主网上。
以下是目前提出的预编译合约:
- EIP-2537:用于 BLS12-381 曲线操作的预编译合约
- EIP-7212:用于 secp256r1 曲线支持的预编译合约
- EIP-7545:用于 Verkle 证明验证的预编译合约
- EIP-5988:添加 Poseidon 哈希函数的预编译合约
引入新的预编译合约需要仔细评估其对网络的影响。 gas 成本计算不当的预编译合约可能会通过消耗超出预期的资源导致拒绝服务(DoS)攻击。此外,增加预编译合约的数量可能会导致 EVM 客户端中的代码膨胀,增加验证者的负担
选择预编译合约的密码学函数及其参数时必须在安全性和效率之间取得平衡。这些参数通常在预编译合约的逻辑中预先设定,因为允许用户定义的参数可能会带来安全风险。此外,为广泛的参数范围优化密码学函数对于实现快速执行来说是一个挑战,而快速执行是预编译合约的基础要求
移除预编译合约
目前正在讨论是否移除那些过时、使用率低或影响客户端软件效率的预编译合约。例如,Identity 预编译合约(已被 MCOPY 操作码取代)、RIPEMD-160 和某些 BLAKE 函数
与完全移除不同,这些预编译合约可以迁移到高效的智能合约实现中。这种方法可以确保功能的延续,但 gas 成本相应会增加
具体实现
Besu:org.hyperledger.besu.evm.precompileGeth:实现在 core/vm/contracts.go 文件中Nethermind:在 Nethermind.EVM.Precompiles 命名空间实现Reth:实现在 REVM Precompiles crates
研究
一种被称为“渐进式预编译合约” 的建议方法旨在改进部署流程。这些预编译合约将位于确定性的 CREATE2 地址上,允许用户合约与相同地址交互,无论预编译合约是否已在主网或特定的 Layer 2 解决方案上启用。这种方法可在原生客户端预编译合约可用时确保更顺畅的过渡。
引用资源
- Appendix E: Ethereum Yellow Paper.
- Week 10: Precompiles overview by Danno Ferrin
- Catalog of EVM Precompile
- Go Ethereum Precompile Implementation.
- A Prehistory of the Ethereum Protocol
- Stack Exchange: What's a precompiled contract and how are they different from native opcodes?
- Stack Exchange: Why aren't more common algorithms done as precompiles?
- A call, a precompile and a compiler walk into a bar
执行层中的数据结构
执行客户端存储当前状态和历史区块链数据。在实际应用中,Ethereum 数据通常以类似 Trie(前缀树)结构的方式存储,主要使用 Merkle Patricia 树。
RLP
Merkle 树概述
Merkle 树是一种基于哈希的数据结构,能够保证数据完整性,且能高效验证数据是否被篡改。它是一种树形结构,其中叶节点存储数据值,每个非叶节点存储其子节点的哈希值。
Merkle 树通过生成整个交易集的数字指纹来存储区块中的所有交易。它允许用户验证某笔交易是否包含在一个区块中。Merkle 树是通过反复计算节点对的哈希值直到只剩下一个哈希值来构建的。这个哈希值被称为 Merkle 根(Merkle Root),或者根哈希(Root Hash)。Merkle 树是以自底向上的方式构建的。
值得注意的是,Merkle 树是一种二叉树,因此它需要偶数个叶子节点。如果交易的数量是奇数,那么最后一个哈希值会被重复一次,以确保叶子节点数量为偶数。
Merkle 树提供了一种防篡改的结构,用于存储交易数据。哈希函数具有雪崩效应(Avalanche Effect),即数据的微小变化会导致结果哈希值发生巨大变化。因此,如果叶子节点中的数据被修改,根哈希值将与预期的值不匹配。你可以尝试自己使用 SHA-256 哈希函数来进行验证。如果想了解更多关于哈希的内容,你可以参考这里。
Merkle 根(Merkle Root)被存储在区块头中。要了解更多关于以太坊区块结构的内容(链接将在相关文档准备好后提供)。
主父节点称为根节点,因此其中的哈希值就是根哈希(Root Hash)。对于单个 SHA-256 哈希,生成两个不同状态的相同根哈希的几率极其小(大约是 1/1.16x10^77),并且任何试图修改状态的操作都会导致不同的状态根哈希。
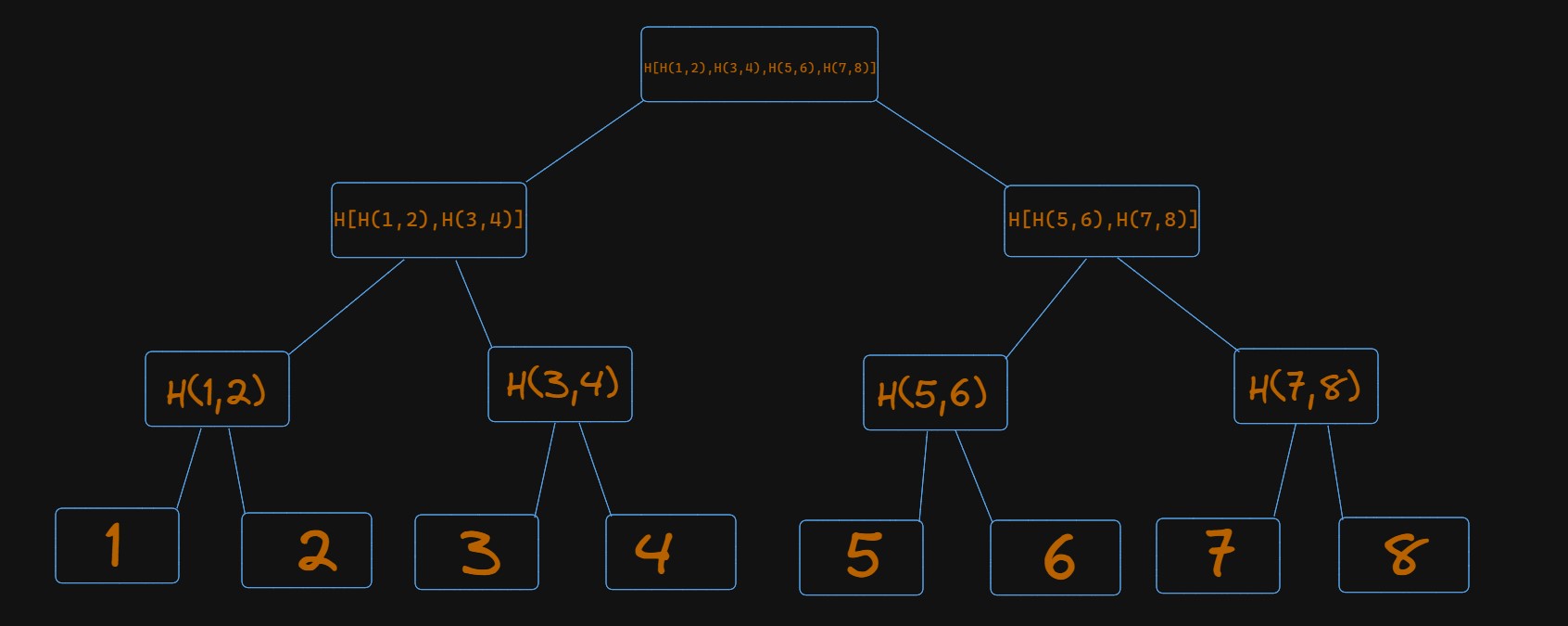
下图展示了 Merkle 树工作原理的简化版本:
- 叶子节点包含实际数据(为简化,例子中使用的是数字)。
- 每个非叶子节点是其子节点哈希的结果。
- 第一层的非叶子节点包含其子叶子节点的哈希值 Hash(1,2)。
- 同样的过程会一直持续,直到到达树顶,最终形成一个包含所有先前哈希值的哈希值 Hash[Hash(1,2), Hash(3,4), Hash(5,6), Hash(7,8)]。
以太坊 Merkle 树更多内容可以参考这里。
Patricia 树概述
Patricia Trie(也叫 Radix Trie)是 n 叉字典树,与 Merkle 树不同,它用于数据存储而非验证。
Patricia Trie 是一种树形数据结构,所有数据均存储在叶子节点。每个非叶子节点是唯一标识数据的字符串中的一个字符或一个字符序列。我们使用这个唯一标识通过字符节点导航,最终到达数据所在位置。因此,它在数据检索方面非常高效。。
Patricia Trie 通过消除只有一个子节点的冗余节点,比传统的 Trie 结构更节省空间。它通过在键之间共享前缀来实现紧凑性。这意味着,多个键之间的公共前缀会被共享,从而减少整体存储需求。
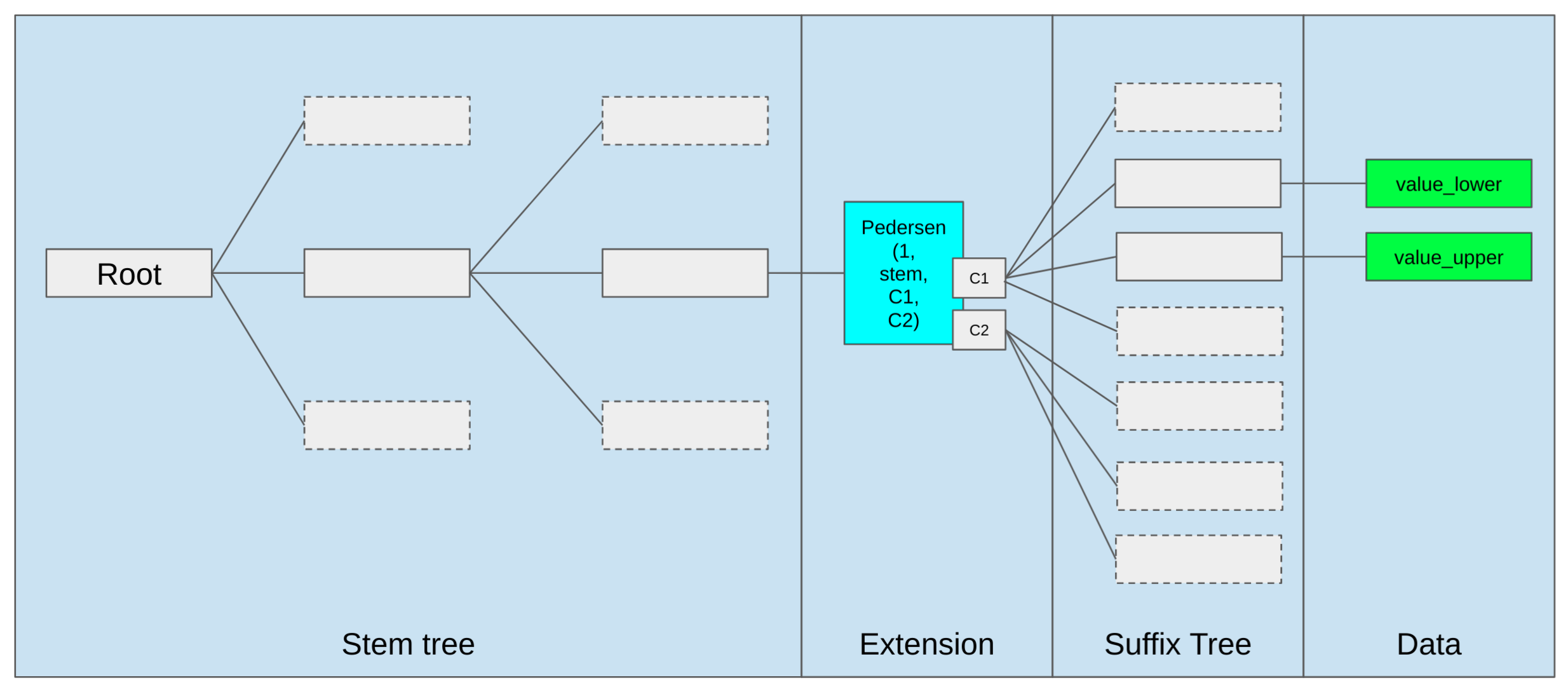
以太坊中的 Merkle Patricia Trie
以太坊用于存储执行层状态的主要数据结构是 Merkle Patricia Trie(简称 MPT,发音为 “try”)。之所以命名为 Merkle Patricia Trie,是因为它结合了 Merkle 树和 PATRICIA(Practical Algorithm To Retrieve Information Coded in Alphanumeric)算法的特点,并且它的设计旨在高效地检索构成以太坊状态的各个数据项。
MPT 中有三种类型的节点:
- 分支节点(Branch Nodes):一个分支节点由一个 17 元素的数组构成,其中包括一个节点值和 16 个分支。这个节点类型是 MPT 进行分支和遍历的主要机制。
- 扩展节点(Extension Nodes):这些节点作为 MPT 中的优化节点。当一个分支节点只有一个子节点时,扩展节点就发挥作用。为了避免为每个分支重复路径,MPT 会将路径压缩为一个扩展节点,保存路径和子节点的哈希值。
- 叶子节点(Leaf Nodes):一个叶子节点代表一个键值对。值是 MPT 节点的内容,而键是节点的哈希值。叶子节点存储特定的键值数据。
每个节点都有一个哈希值。节点的哈希值是其内容的 SHA-3 哈希值,这个哈希值也作为引用该节点的键。Nibbles(半字节)是 MPT 中用于区分键值的单位,代表一个十六进制数字。每个 Trie 节点最多可以分支到 16 个子节点,从而确保了紧凑的表示和高效的内存使用。
TODO:Patricia 树图示
以太坊
以太坊用于存储执行层状态的主要数据结构是 Merkle Patricia Trie(发音为 “try”)。它之所以被命名为 Merkle Patricia Trie,是因为它结合了 Merkle 树的特性,并采用了 PATRICIA(Practical Algorithm To Retrieve Information Coded in Alphanumeric)算法的特点,同时它的设计旨在高效地检索构成以太坊状态的各个数据项。
以太坊的状态被存储在四个不同的修改版 Merkle Patricia Tries(MMPTs)中:
- 交易 Trie(Transaction Trie)
- 回执 Trie(Receipt Trie)
- 世界状态 Trie(World State Trie)
- 账户状态 Trie(Account State Trie)
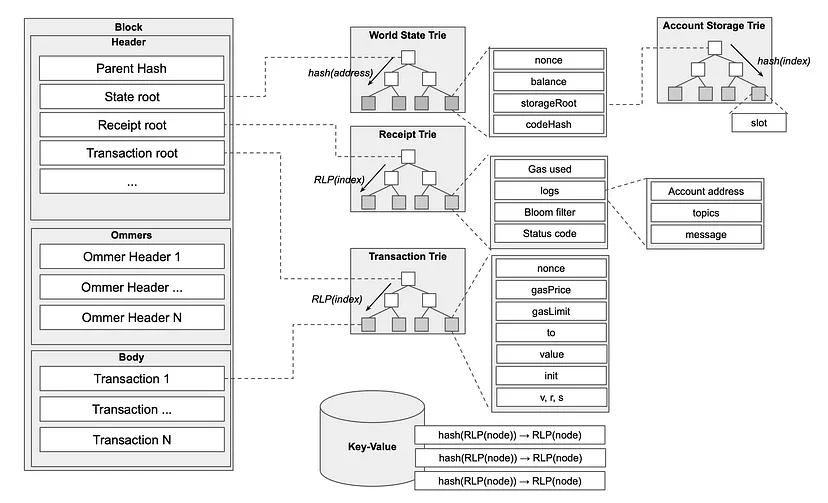
在每个区块中,都有一个交易、回执和状态 trie,这些 trie 在区块头部通过其根哈希值进行引用。对于以太坊上每个部署的合约,都有一个存储 trie 用于保存该合约的持久变量,每个存储 trie 都通过其根哈希值在状态 trie 中对应合约地址的状态账户对象中进行引用。
交易 Trie
交易 Trie 是一个数据结构,用于存储特定区块中的所有交易。每个区块都有自己的交易 Trie,存储该区块中包含的相应交易。以太坊是一个基于交易的状态机,这意味着以太坊中的每一个操作或状态变更都源于一笔交易。每个区块由区块头和交易列表(以及其他内容)组成。因此,一旦交易被执行并且区块被最终确认,该区块的交易 Trie 就无法再被更改(与世界状态 Trie 不同)。
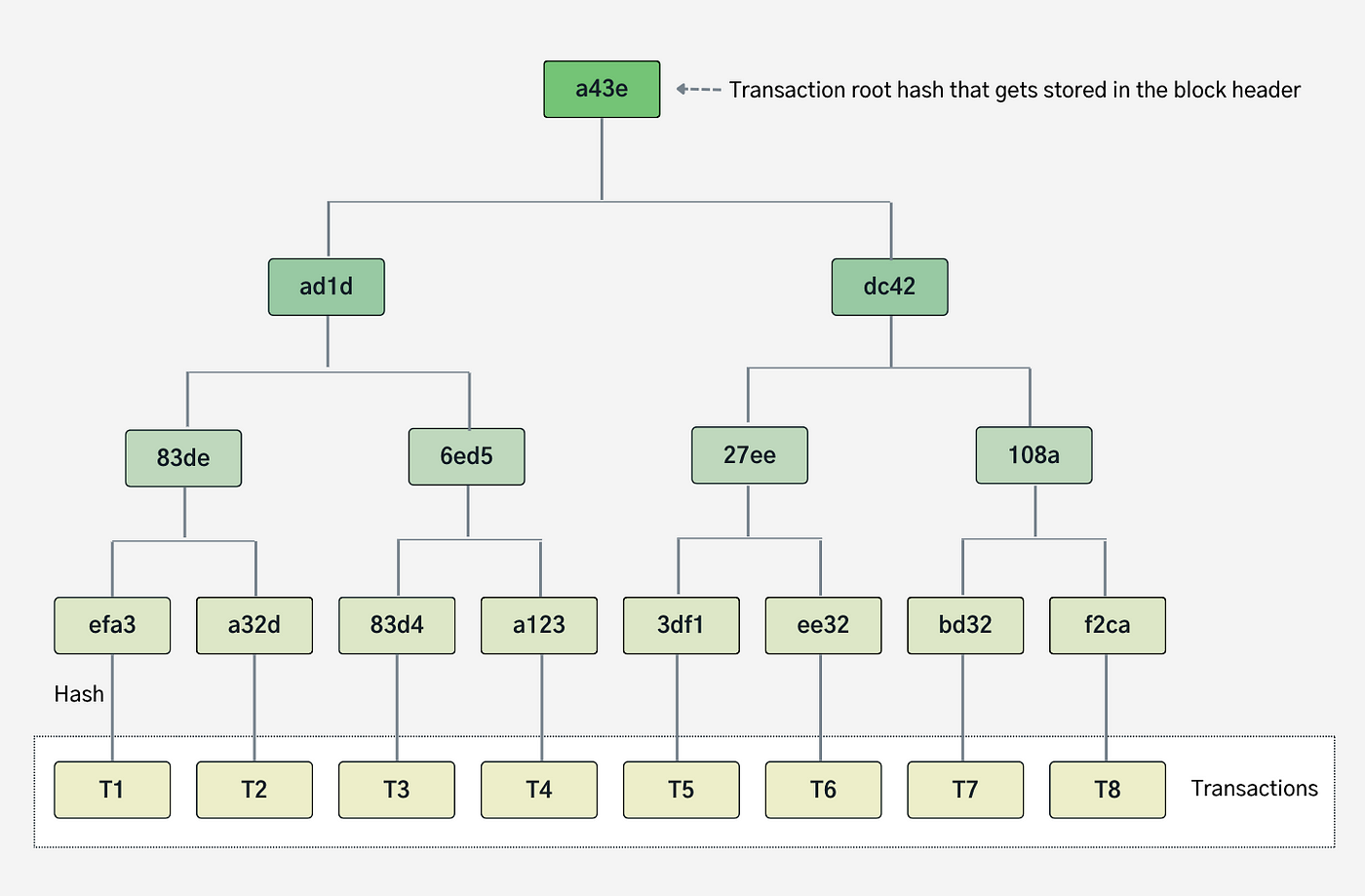
每笔交易在交易 Trie 中有一个映射,其中键是交易的索引,值是交易 T。交易索引和交易本身都采用 RLP 编码。它们组成一个键值对,存储在 Trie 中:𝑅𝐿𝑃 (𝑖𝑛𝑑𝑒𝑥) → 𝑅𝐿𝑃 (𝑇)
交易 T 的结构包括以下内容:
- Nonce:每次相同发送者提交新交易时,nonce 会递增。这个值用于跟踪交易的顺序,并防止重放攻击。
- maxPriorityFeePerGas:交易中用于给验证者的小费的最大 Gas 价格。
- gasLimit:交易可以消耗的最大 Gas 单位数。
- maxFeePerGas:交易中每单位 Gas 愿意支付的最大费用(包括 baseFeePerGas 和 maxPriorityFeePerGas)。
- from:交易发起者的地址,该地址将签署交易。必须是外部拥有账户(EOA),因为合约账户不能发送交易。
- to:接收资金的账户地址,或为合约创建时为零。
- value:从发送者转账给接收者的 ETH 数量。
- input data:可选字段,包含任意数据。
- data:消息调用的输入数据,以及消息的签名。
- (v, r, s):编码发送者签名的值。作为发送者的标识符。
TODO: 解释收据树(Receipt Trie)
TODO: 解释全局状态树(World State Trie)
TODO: 解释存储树(Storage Trie)
未来的实现
Verkle 树
Verkle 树是一种新的数据结构,旨在取代当前的 Merkle Patricia Trie(MPT)。它的名称来自“向量承诺(Vector commitment)“和“Merkle 树”这两个概念的结合,设计上比当前的 MPT 更高效、更具可扩展性。Verkle 树是一种基于 Trie 的数据结构,它用轻量级的证明替代了 MPT 中使用的重型证明。Verkle 树是以太坊“Verge”升级的关键部分。它们能够使无状态客户端变得更加高效和可扩展。
Verkle 树的结构
Verkle 树的布局结构与 MPT 类似,但树的基数(即每个节点的子节点数量)不同。就像 MPT 一样,它有根节点、内部节点、扩展节点和叶节点。唯一的区别在于树的键的大小,MPT 使用的是 20 字节的键,而 Verkle 树使用的是 32 字节的键,其中 31 字节作为树的主干,而最后 1 字节用于存储具有几乎相同主干地址或相邻代码块的数据(开启相同的承诺会更便宜)。此外,由于在计算证明数据时,算法使用了 252 位作为字段元素,因此使用 31 字节作为树的后缀是更方便的。这样,主干数据可以承诺两种不同的承诺,分别是 0-127 和 128-255,即相同键的下值和上值,从而覆盖整个后缀空间。有关更多信息,请参阅此处。
MPT 和 Verkle 树的主要区别
Merkle/MP 树的深度很大,因为其树结构在每个节点处是二叉的(2/16 叉树)。这意味着,叶节点的证明数据是从根节点到叶节点的路径。由于每一层还需要包含兄弟节点的哈希数据,这使得对于一棵大的树来说,证明数据会非常庞大。而 Verkle 树的宽度较大,因为其树结构在每个节点处是 n 叉的。因此,叶节点的证明数据是从叶节点到根节点的路径,这对于一棵大的树来说可以非常小。目前,Verkle 树建议每个节点有 256 个子节点。更多信息参与此处。
Merkle/MP 树的中间节点是子节点的哈希值,而 Verkle 树的节点则携带一种特殊类型的哈希,称为“向量承诺”(vector commitments),用于对其子节点进行承诺。这意味着,在 Verkle 树中,叶节点的证明数据是沿着从叶节点到根节点路径的子节点的承诺。此外,通过聚合这些承诺来计算证明,使得验证过程非常紧凑。有关证明系统的更多信息,请参阅相关内容。
为什么选择 Verkle 树?
要使客户端无状态(stateless),关键在于客户端验证区块时无需存储整个或之前的区块链状态。新接收的区块应能提供客户端验证该区块所需的必要数据。这些额外的证明数据称为见证数据(witness),使得无状态客户端能够在不需要完整状态的情况下验证数据。通过区块内的信息,客户端还应该能够随着每个传入区块的到来来维护或增长本地状态。使用这种方式,客户端保证对当前区块(以及其后验证的区块)的状态转换是正确的。这并不保证对当前区块引用的先前区块的状态是正确的,因为区块生产者可能构建在无效或非规范的区块之上。
Verkle 树旨在在存储和通信成本方面更加高效。对于 1000 个叶子/数据,一个二叉 Merkle 树大约需要 4MB 的证明数据,而 Verkle 树则将其减少到 150KB。如果我们将证明数据包含在区块中,它不会对区块大小产生太大影响,但它将使无状态客户端更高效和可扩展。通过这种方式,无状态客户端将能够信任计算结果,而无需存储整个状态。
然而,向新的 Verkle 树数据库过渡面临着重大挑战。为了安全地创建新的 Verkle 数据,客户端需要从现有的 MPT 中生成它们,这需要大量的计算和空间。目前,Verkle 数据库的分发和验证仍在研究中。
参考资料
- More on Merkle Patricia Trie
- More on Verkle Tree
- Verge transition
- Implementing Merkle Tree and Patricia Trie • archived
交易剖析
交易 是由 外部账户 发布的经过加密签名的指令,通过 JSON-RPC 广播到整个网络。
交易包含以下字段:
-
nonce (): 一个整数值,等于发送方已发送交易的数量。Nonce 的用途包括:
- 防止重放攻击:假设 Alice 向 Bob 发送 1 ETH 的交易,Bob 可能试图将相同的交易重新广播到网络中,从 Alice 的账户中获取额外的资金。由于交易使用了唯一的 nonce,如果 Bob 再次发送,EVM 将直接拒绝交易,从而保护 Alice 的账户免受未经授权的重复交易。
- 确定合约账户地址:在
合约创建模式下,nonce 和发送者地址一起用于确定合约账户地址。 - 替换交易:当交易因低 Gas 费卡住时,矿工通常允许用相同 nonce 的交易替换原交易。一些钱包可能提供取消交易的选项,这本质上是发送一个新的交易,其具有相同的 nonce、更高的 Gas 价格和 0 的数值,从而覆盖原来的待处理交易。然而,替换交易的成功并不保证,因为这取决于矿工的行为和网络条件。
-
gasPrice (): 一个整数值,表示每单位 Gas 支付的 Wei 数量。Wei 是以太坊中最小的单位。。Gas 价格用于决定交易的执行优先级。Gas 价格越高,交易越有可能被矿工优先打包进区块。
-
gasLimit (): 一个整数值,表示该交易执行时允许使用的最大 Gas 数量。如果执行过程中 Gas 超过了 gasLimit,交易将被停止。
-
to (): 交易接收方的 20 字节地址。
to字段还决定了交易的模式或用途:
to 的值 | 交易模式 | 描述 |
|---|---|---|
| 空 | 合约创建模式 | 该交易用于创建一个新的合约账户。 |
| 外部账户 | 价值转移 | 该交易用于向一个外部账户转移以太币。 |
| 合约账户 | 合约执行 | 该交易用于调用现有的智能合约代码。 |
-
value (): 一个整数值,表示转移到此交易接收方的 Wei 数量。在
合约创建模式下,value 是新创建合约账户的初始余额。 -
data () 或 init(): 一个无限大小的字节数组,指定 EVM 的输入。在
合约创建模式下,此值被视为初始化字节码,否则是输入数据的字节数组。 -
Signature (): ECDSA 签名,由发送方提供。
合约创建
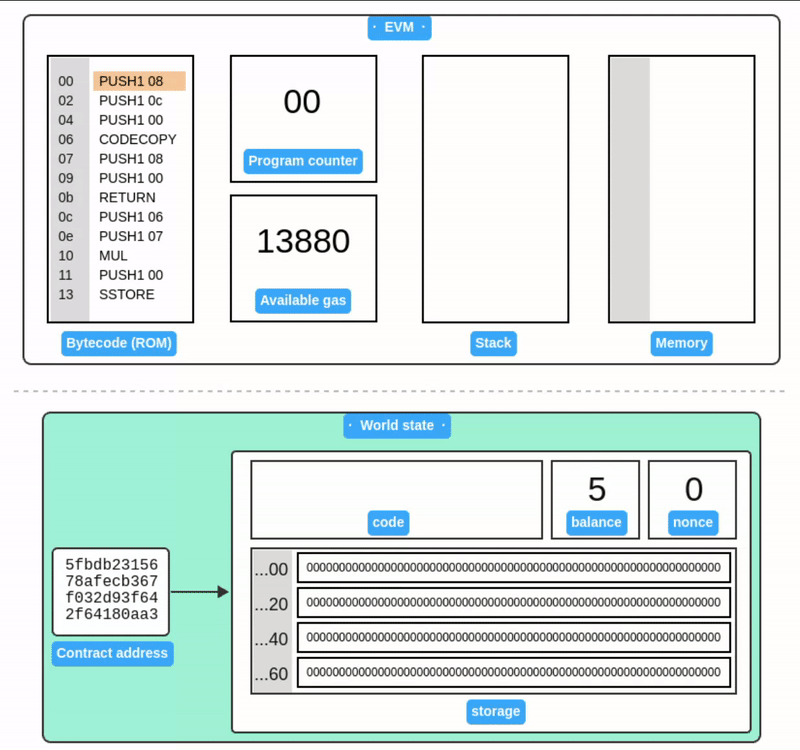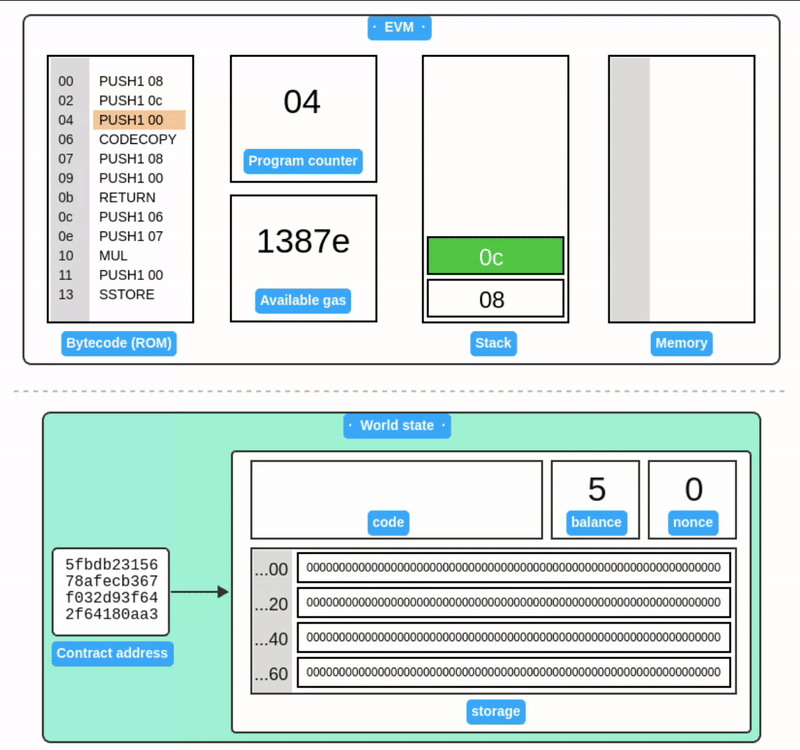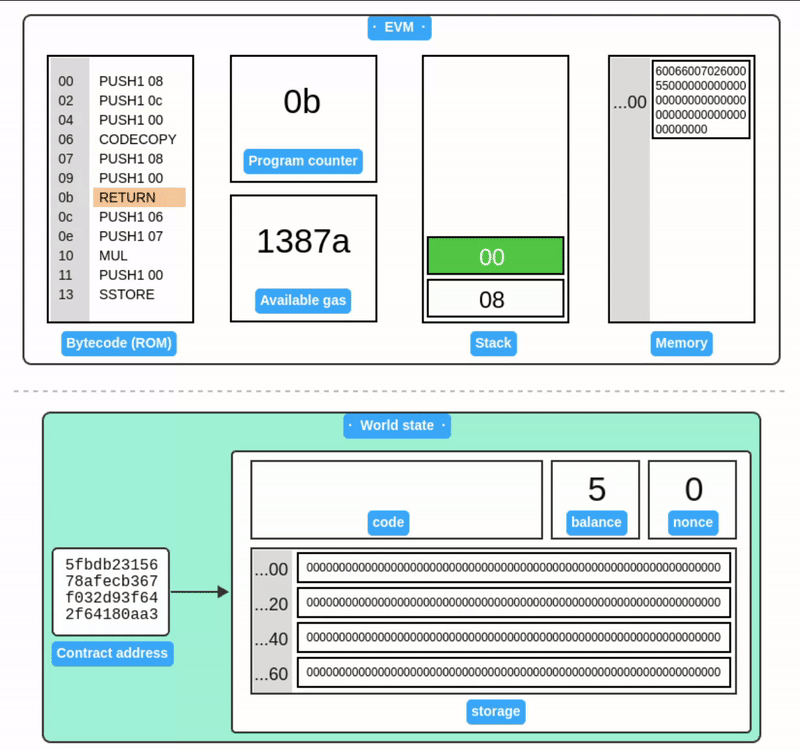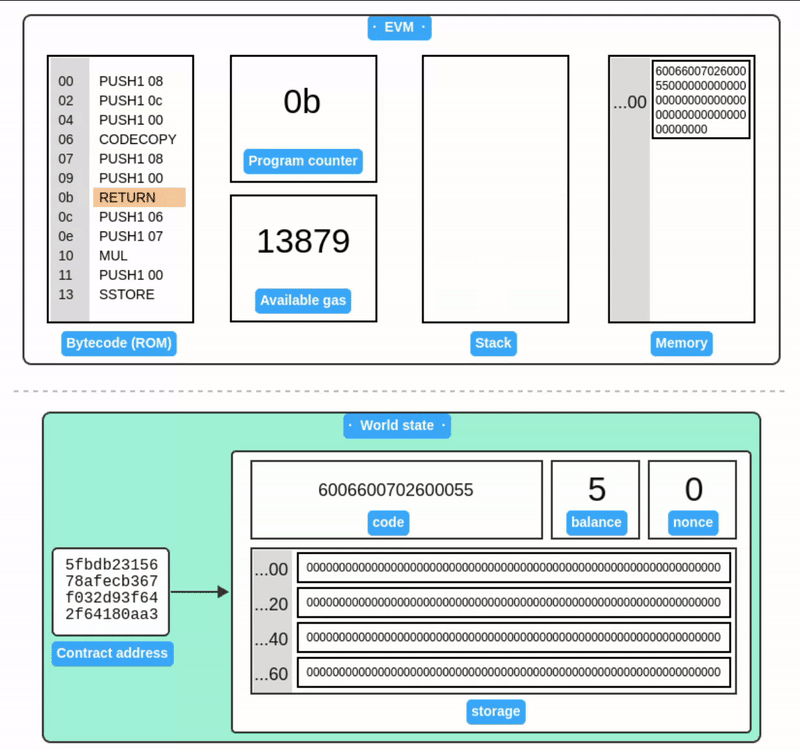
让我们将以下代码部署到一个新的合约账户:
[00] PUSH1 06 // 推入 06
[02] PUSH1 07 // 推入 07
[04] MUL // 乘法
[05] PUSH1 0 // 推入 00 (存储地址)
[07] SSTORE // 将结果存储到存储槽 00
括号内的数字表示指令的偏移量。对应的字节码:
6006600702600055
现在,让我们准备交易的 init 值,以部署这个字节码。实际上,init 由两个片段组成:
<init bytecode> <runtime bytecode>
init 仅在账户创建时由 EVM 执行一次。init 代码执行的返回值是 runtime bytecode,它存储为合约账户的一部分。每次合约账户收到交易时,都会执行 runtime bytecode。
让我们准备我们的 init 代码,使其返回我们的 runtime 代码:
// 1. Copy to memory
[00] PUSH1 08 // PUSH1 08 (length of our runtime code)
[02] PUSH1 0c // PUSH1 0c (offset of the runtime code in init)
[04] PUSH1 00 // PUSH1 00 (destination in memory)
[06] CODECOPY // Copy code running in current environment to memory
// 2. Return from memory
[07] PUSH1 08 // PUSH1 08 (length of return data)
[09] PUSH1 00 // PUSH1 00 (memory location to return from)
[0b] RETURN // Return the runtime code and halt execution
// 3. Runtime code (8 bytes long)
[0c] PUSH1 06
[0e] PUSH1 07
[10] MUL
[11] PUSH1 0
[13] SSTORE
这段代码做了两件简单的事情:首先,将 runtime 字节码复制到内存中,然后从内存中返回 runtime 字节码。
init 字节码:
6008600c60003960086000f36006600702600055
接下来,准备交易的 payload:
[
"0x", // nonce (zero nonce, since first transaction)
"0x77359400", // gasPrice (we're paying 2000000000 wei per unit of gas)
"0x13880", // gasLimit (80000 is standard gas for deployment)
"0x", // to address (empty in contract creation mode)
"0x05", //value (we'll be nice and send 5 wei to our new contract)
"0x6008600c60003960086000f36006600702600055", // init code
];
payload 的排列需要遵循特定的顺序。
对于这个例子,我们将使用 Foundry 在本地部署交易。Foundry 是一个以太坊开发工具包,提供了以下命令行工具:
- Anvil : 一个本地以太坊节点,专为开发场景设计。
- Cast: 一个用于执行以太坊 RPC 调用的工具。
安装并启动 anvil 本地节点。
$ anvil
_ _
(_) | |
__ _ _ __ __ __ _ | |
/ _` | | '_ \ \ \ / / | | | |
| (_| | | | | | \ V / | | | |
\__,_| |_| |_| \_/ |_| |_|
0.2.0 (5c3b075 2024-03-08T00:17:08.007462509Z)
https://github.com/foundry-rs/foundry
Available Accounts
==================
(0) "0xf39Fd6e51aad88F6F4ce6aB8827279cffFb92266" (10000.000000000000000000 ETH)
.....
Private Keys
==================
(0) 0xac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80
.....
Listening on 127.0.0.1:8545
使用 anvil 的 dummy 账户签署交易:
$ node sign.js '[ "0x", "0x77359400", "0x13880", "0x", "0x05", "0x6008600c60003960086000f36006600702600055" ]' ac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80
f864808477359400830138808005946008600c60003960086000f360066007026000551ca01446316c9bdcbe0cb87fac0b08a00e59552634c96d0d6e2bd522ea0db827c1d0a0170680b6c348610ef150c1b443152214203c7f66288ea6332579c0cdfa86cc3f
请参阅 附录 A 以获取
sign.js辅助脚本。
最后,使用 cast 提交交易:
$ cast publish f864808477359400830138808005946008600c60003960086000f360066007026000551ca01446316c9bdcbe0cb87fac0b08a00e59552634c96d0d6e2bd522ea0db827c1d0a0170680b6c348610ef150c1b443152214203c7f66288ea6332579c0cdfa86cc3f
{
"transactionHash": "0xdfaf2817f19963846490b330ae33eba7b42872e8c8bd111c8d7ea3846c84cd51",
"transactionIndex": "0x0",
"blockHash": "0xfde1475a716583d847f858c5db3e54156983b39e3dbefaa5829416e6e60a788a",
"blockNumber": "0x1",
"from": "0xf39fd6e51aad88f6f4ce6ab8827279cfffb92266",
"to": null,
"cumulativeGasUsed": "0xd67e",
"gasUsed": "0xd67e",
// Newly created contract address 👇
"contractAddress": "0x5fbdb2315678afecb367f032d93f642f64180aa3",
"logs": [],
"status": "0x1",
"logsBloom": "0x0...",
"effectiveGasPrice": "0x77359400"
}
查询本地 anvil 节点确认代码已部署:
$ cast code 0x5fbdb2315678afecb367f032d93f642f64180aa3
0x6006600702600055
初始余额可用:
$ cast balance 0x5fbdb2315678afecb367f032d93f642f64180aa3
5
下图模拟了合约创建的过程:
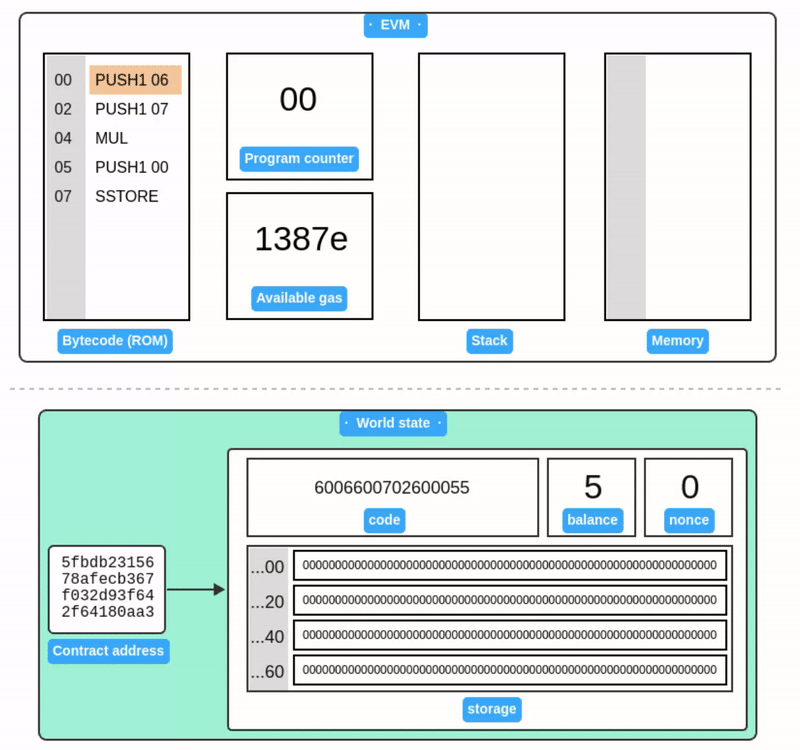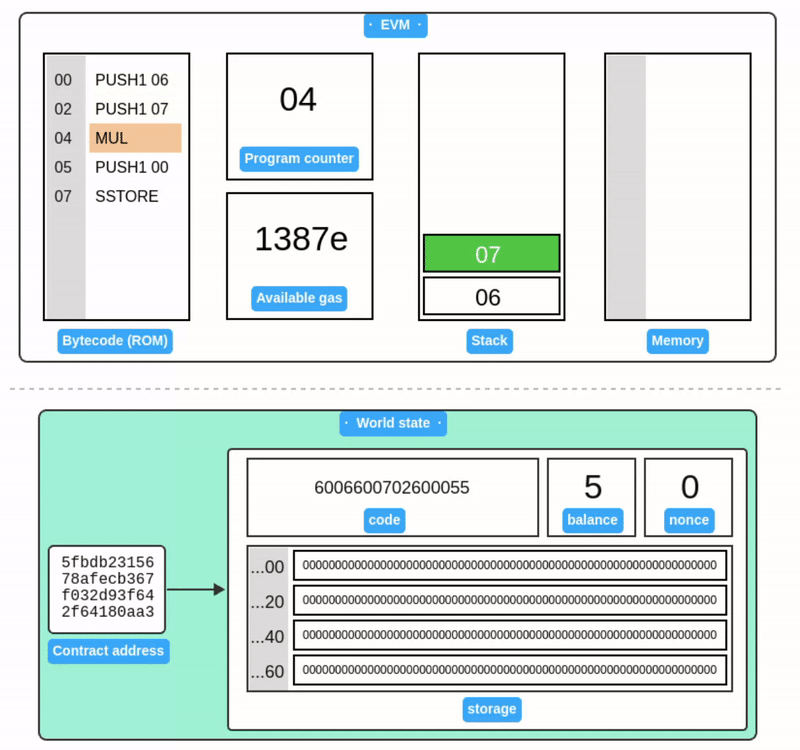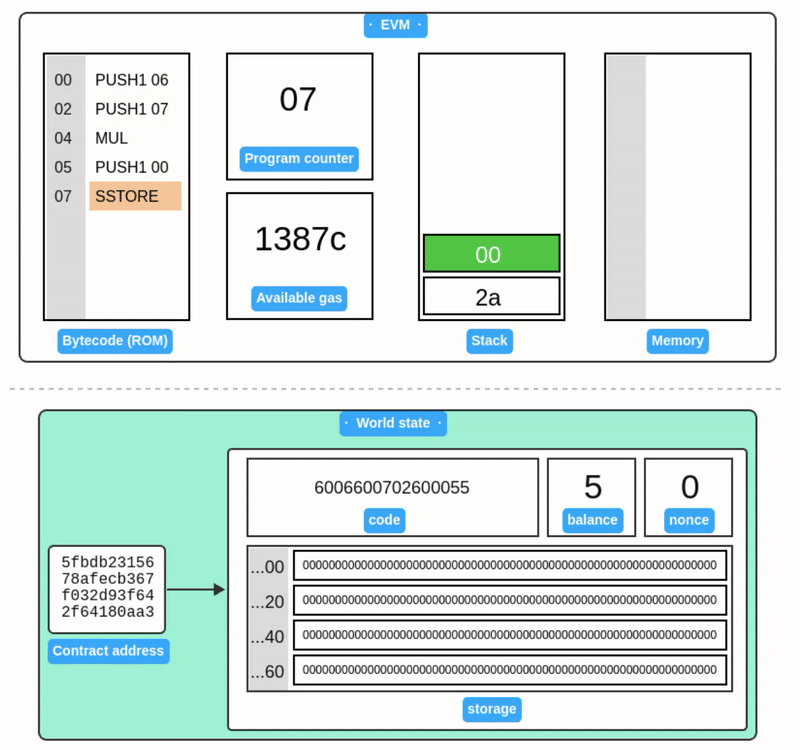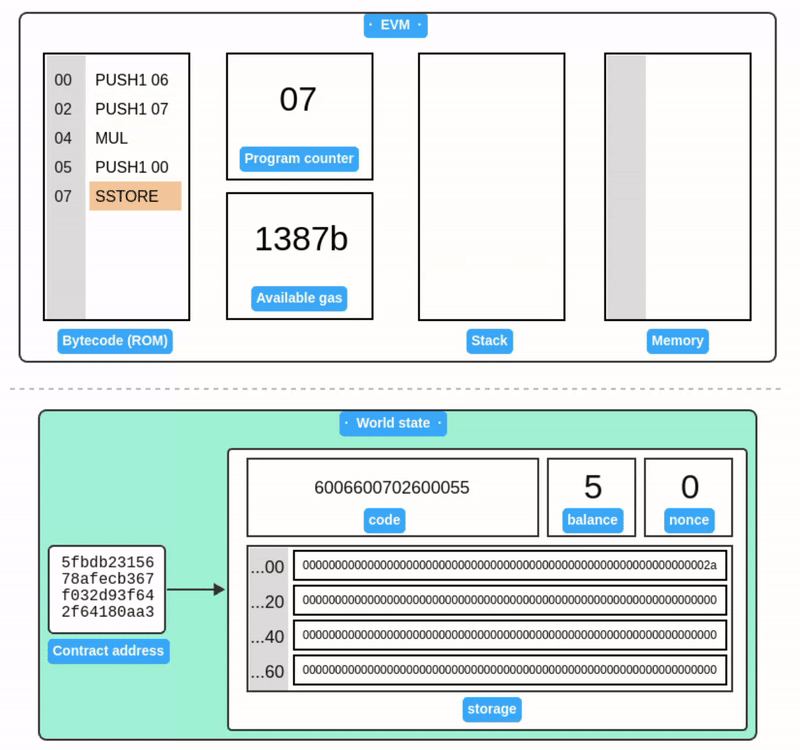
合约代码执行
我们部署的这个简单合约功能是将 6 和 7 相乘并把结果保存到存储槽 0。现在让我们发送一笔交易来执行这个合约。
这笔交易的 payload 结构和之前类似,但有几点不同:to 字段需要填入我们刚才部署的智能合约地址,而 value 和 data 字段则留空:
[
"0x1", // nonce (increased by 1)
"0x77359400", // gasPrice (we're paying 2000000000 wei per unit of gas)
"0x13880", // gasLimit (80000 is standard gas for deployment)
"0x5fbdb2315678afecb367f032d93f642f64180aa3", // to address ( address of our smart contract)
"0x", // value (empty; not sending any ether)
"0x", // data (empty)
];
对交易进行签名:
$ node sign.js '[ "0x1", "0x77359400", "0x13880", "0x5fbdb2315678afecb367f032d93f642f64180aa3", "0x", "0x"]' ac0974bec39a17e36ba4a6b4d238ff944bacb478cbed5efcae784d7bf4f2ff80
f86401847735940083013880945fbdb2315678afecb367f032d93f642f64180aa380801ba047ae110d52f7879f0ad214784168406f6cbb6e72e0cab59fa4df93da6494b578a02c72fcdea5b7838b520664186707d1465596e4ad4eaf8781a721530f8b8dd5f2
发布交易:
$ cast publish f86401847735940083013880945fbdb2315678afecb367f032d93f642f64180aa380801ba047ae110d52f7879f0ad214784168406f6cbb6e72e0cab59fa4df93da6494b578a02c72fcdea5b7838b520664186707d1465596e4ad4eaf8781a721530f8b8dd5f2
{
"transactionHash": "0xc82a658b947c6083de71a0c587322e8335448e65e7310c04832e477558b2b0ef",
"transactionIndex": "0x0",
"blockHash": "0x40dc37d9933773598094ec0147bef5dfe72e9654025bfaa80c4cdbf634421384",
"blockNumber": "0x2",
"from": "0xf39fd6e51aad88f6f4ce6ab8827279cfffb92266",
"to": "0x5fbdb2315678afecb367f032d93f642f64180aa3",
"cumulativeGasUsed": "0xa86a",
"gasUsed": "0xa86a",
"contractAddress": null,
"logs": [],
"status": "0x1",
"logsBloom": "0x0...",
"effectiveGasPrice": "0x77359400"
}
使用 cast 读取存储槽 0 的值:
$ cast storage 0x5fbdb2315678afecb367f032d93f642f64180aa3 0x
0x000000000000000000000000000000000000000000000000000000000000002a
果然,结果正是 42 (0x2a) 🎉。
合约执行的模拟:
附录 A:交易签名器
signer.js:一个用于签署交易的简单 node.js 脚本。请看注释中的说明:
/**
* 用于签署交易 payload 数组的工具脚本。
* 用法:node sign.js '[payload]' [private key]
*/
const { rlp, keccak256, ecsign } = require("ethereumjs-util");
// 解析命令行参数
const payload = JSON.parse(process.argv[2]);
const privateKey = Buffer.from(process.argv[3].replace("0x", ""), "hex");
// 验证私钥长度
if (privateKey.length != 32) {
console.error("私钥必须是64个字符长!");
process.exit(1);
}
// 第1步:将 payload 编码为 RLP 格式
// 了解更多:https://ethereum.org/en/developers/docs/data-structures-and-encoding/rlp/
const unsignedRLP = rlp.encode(payload);
// 第2步:对 RLP 编码后的 payload 进行哈希
// 了解更多:https://ethereum.org/en/glossary/#keccak-256
const messageHash = keccak256(unsignedRLP);
// 第3步:签名消息
// 了解更多:https://epf.wiki/#/wiki/Cryptography/ecdsa
const { v, r, s } = ecsign(messageHash, privateKey);
// 第4步:将签名附加到 payload
payload.push(
"0x".concat(v.toString(16)),
"0x".concat(r.toString("hex")),
"0x".concat(s.toString("hex"))
);
// 第5步:输出 RLP 编码后的已签名交易
console.log(rlp.encode(payload).toString("hex"));
更多资源
- 📝 Gavin Wood, "Ethereum Yellow Paper."
- 📘 Andreas M. Antonopoulos, Gavin Wood, "Mastering Ethereum."
- 📝 Ethereum.org, "RLP Encoding."
- 📝 Ethereum.org, "Transactions."
- 📝 Random Notes, "Signing transactions the hard way." • archived
- 🎥 Lefteris Karapetsas, "Understanding Transactions in EVM-Compatible Blockchains."
- 🎥 Austin Griffith, "Transactions - ETH.BUILD."
- 🧮 Paradigm, "Foundry: Ethereum development toolkit."
JSON-RPC
JSON-RPC 规范是一种基于OpenRPC的、使用 JSON 编码的远程过程调用协议。它允许在服务器上远程调用函数,并返回结果。
它是执行 API 规范的一部分,该规范提供了一套与以太坊区块链交互的方法。
更为人所熟知的是,该规范阐述了用户如何通过客户端与网络进行交互,以及共识层(CL)与执行层(EL)如何通过引擎 API 相互作用的方式。
本节将详细介绍 JSON-RPC 方法。
API 规范
JSON-RPC 方法按照指定为方法前缀的命名空间进行分组。尽管它们各有不同的用途,但所有方法都共享一个通用结构,并且在所有实现中必须表现出相同的行为:
{
"id": 1,
"jsonrpc": "2.0",
"method": "<prefix_methodName>",
"params": [...]
}
其中:
id: 请求的唯一标识符。jsonrpc: JSON-RPC 协议的版本。method: 将要调用的方法。params: 方法的参数。如果该方法不需要任何参数,它可以是一个空数组。其他参数如果没有提供,可能会有默认值。
命名空间
每个方法由一个命名空间前缀和方法名称组成,二者之间用下划线分隔。
以太坊客户端必须实现规范所要求的基本 RPC 方法集,以便与区块链网络进行交互。此外,还有一些特定于客户端的方法,用于控制节点或实现额外的独特功能。请始终参阅客户端文档,查看可用的方法和命名空间。例如,请注意 Geth 和 Reth 文档中不同命名空间的区别。
以下是一些常见命名空间的示例:
| 命名空间 | 描述 | 敏感性 |
|---|---|---|
| eth | eth API 允许你与以太坊进行交互。 | 可能 |
| web3 | web3 API 为 web3 客户端提供实用功能。 | 否 |
| net | net API 提供节点网络信息访问能力。 | 否 |
| txpool | txpool API 允许你检查交易池。 | 否 |
| debug | debug API 提供多种方法来检查以太坊状态,包括 Geth 风格的追踪。 | 否 |
| trace | trace API 提供多种方法来检查以太坊状态,包括 Parity 风格的追踪。 | 否 |
| admin | admin API 允许你配置自己的节点。 | 是 |
| rpc | rpc API 提供关于 RPC 服务器及其模块的信息。 | 否 |
“敏感性”意味着接口可以用来设置节点,比如 admin,或访问存储在节点中的账户数据,就像 eth 那样。
现在,让我们来看看一些方法,了解它们是如何构建的以及它们的作用:
Eth
Eth 可能是最常用的命名空间,它提供了对以太坊网络的基本访问,例如,钱包需要使用它来读取余额和创建交易。 这里只列出了一些方法,完整的列表可以在 Ethereum JSON-RPC specification 中找到。
| 方法 | 参数 | 描述 |
|---|---|---|
| eth_blockNumber | 无必须参数 | returns the number of the most recent block |
| eth_call | transaction object | executes a new message call immediately without creating a transaction on the block chain |
| eth_chainId | 无必须参数 | returns the current chain id |
| eth_estimateGas | transaction object | makes a call or transaction, which won't be added to the blockchain and returns the used gas, which can be used for estimating the used gas |
| eth_gasPrice | 无必须参数 | returns the current price per gas in wei |
| eth_getBalance | address, block number | returns the balance of the account of the given address |
| eth_getBlockByHash | block hash, full txs | returns information about a block by hash |
| eth_getBlockByNumber | block number, full txs | returns information about a block by block number |
| eth_getBlockTransactionCountByHash | block hash | returns the number of transactions in a block from a block matching the given block hash |
| eth_getBlockTransactionCountByNumber | block number | returns the number of transactions in a block from a block matching the given block number |
| eth_getCode | address, block number | returns code at a given address in the blockchain |
| eth_getLogs | filter object | returns an array of all logs matching a given filter object |
| eth_getStorageAt | address, position, block number | returns the value from a storage position at a given address |
| 方法 | 参数 | 描述 |
|---|---|---|
| eth_blockNumber | 无必须参数 | 返回最新区块的编号 |
| eth_call | transaction object | 立即执行一个新的消息调用,不在区块链上创建交易 |
| eth_chainId | 无必须参数 | 返回当前链的 ID |
| eth_estimateGas | transaction object | 执行一个调用或交易,不会添加到区块链上,并返回使用的 gas,可用于估算消耗的 gas |
| eth_gasPrice | 无必须参数 | 返回当前每单位 gas 的价格,以 wei 为单位 |
| eth_getBalance | address, block number | 返回给定地址的账户余额 |
| eth_getBlockByHash | block hash, full txs | 通过区块哈希返回区块信息 |
| eth_getBlockByNumber | block number, full txs | 通过区块编号返回区块信息 |
| eth_getBlockTransactionCountByHash | block hash | 通过区块哈希返回指定区块的交易数量 |
| eth_getBlockTransactionCountByNumber | block number | 通过区块编号返回指定区块的交易数量 |
| eth_getCode | address, block number | 返回区块链中指定地址处的代码 |
| eth_getLogs | filter object | 返回与给定过滤器对象匹配的所有日志的数组 |
| eth_getStorageAt | address, position, block number | 返回指定存储位置的值 |
Debug
debug 命名空间提供了一些方法来检查以太坊的状态。通过它可以直接访问原始数据,这对于某些用例(如区块浏览器或研究目的)可能是必需的。这些方法中的一些可能需要在节点上进行大量计算,而在非存档节点上请求历史状态通常是不可行的。因此,公共 RPC 的提供者通常会限制这个命名空间或只允许安全的方法。这些方法中有些可能需要在节点上进行大量的计算,而且在非存档节点上查询历史状态多数情况下是不可行的。因此,公共 RPC 的提供者通常对这一命名空间加以限制,或只允许使用安全的方法。
以下是调试方法的基本示例:
| 方法 | 参数 | 描述 |
|---|---|---|
| debug_getBadBlocks | 无必须参数 | 返回客户端最近看到的坏区块的数组 |
| debug_getRawBlock | block_number | 返回一个 RLP 编码的区块 |
| debug_getRawHeader | block_number | 返回一个 RLP 编码的头 |
| debug_getRawReceipts | block_number | 返回一个 EIP-2718 二进制编码的收据数组 |
| debug_getRawTransactions | tx_hash | 返回一个 EIP-2718 二进制编码的交易数组 |
Engine
Engine API 与上述方法不同。客户端在一个不同的、经过认证的端点上提供 Engine API,而不是普通的 http JSON RPC,因为它不是面向用户的 API。它主要用于共识层与执行层客户端之间的连接,基本上是一个内部节点通信过程。客户端之间的通信涉及关于共识、分叉选择、区块验证等信息的交换:
| 方法 | 参数 | 描述 |
|---|---|---|
| engine_exchangeTransitionConfigurationV1 | Consensus client config | 交换客户端配置 |
| engine_forkchoiceUpdatedV1* | forkchoice_state, payload attributes | 更新分叉选择状态 |
| engine_getPayloadBodiesByHashV1* | block_hash (array) | 给定区块哈希返回对应的执行负载体 |
| engine_getPayloadV1* | forkchoice_state, payload attributes | 从负载构建过程中获取执行负载 |
| debug_newPayloadV1* | tx_hash | 返回执行负载验证 |
那些标有星号(*)的方法具有多个版本,Ethereum JSON-RPC specification 提供了详细的描述。
编码
JSON-RPC 方法的参数编码遵循十六进制编码的约定。
- 数量使用 "0x" 前缀表示为十六进制值。
- 例如,数字 65 表示为 "0x41"。
- 数字 0 表示为 "0x0"。
- 一些无效的用法包括 "0x" 和 "ff"。前者没有后续数字,后者没有以 "0x" 前缀。
- 未格式化的数据,如哈希值、账户地址或字节数组,也使用“0x”前缀进行十六进制编码。
- 例如:0x400(十进制中为 1014)
- 一个无效的例子是 0x400,因为不允许前导零。
传输协议无关
值得一提的是,JSON-RPC 是传输协议无关的,这意味着它可以使用任何传输协议,如 HTTP、WebSockets (WSS),甚至进程间通信 (IPC)。传输协议之间的差异总结如下:
- HTTP 传输提供单向的响应-请求模型,发送响应后连接会被关闭。
- WSS 是双向协议,这意味着连接会一直保持,直到节点或用户显式关闭。支持基于订阅的模型通信,如事件驱动交互。
- IPC 传输协议用于同一台机器上运行的进程之间的通信。它比 HTTP 和 WSS 更快,但不适合远程通信,例如,可以通过本地 JS 控制台使用。
工具使用
有多种方法可以使用 JSON-RPC 方法。其中一种是使用 curl 命令。例如,要获取最新的区块编号,可以使用以下命令:
curl <node-endpoint> \
-X POST \
-H "Content-Type: application/json" \
-d '{"jsonrpc":"2.0","method":"eth_blockNumber","params":[],"id":1}'
请注意,params 字段为空,因为方法默认传递 "latest" 作为值。
另一种方法是使用 Javascript/TypeScript 中的 axios 库。例如,要获取地址余额,可以使用以下代码:
import axios from "axios";
const node = "<node-endpoint>";
const address = "<address>";
const response = await axios.post(node, {
jsonrpc: "2.0",
method: "eth_getBalance",
params: [address, "latest"],
id: 1,
headers: {
"Content-Type": "application/json",
},
});
如你所见,JSON-RPC 方法在 POST 请求中,参数在请求体中传递。 这是客户端和服务器之间使用 OSI 的应用层协议(HTTP 协议)交换数据的一种不同方式。
无论哪种方式,与以太坊网络交互的最常见方法是使用 web3 库,例如 web3py 用于 python 或 web3.js/ethers.js 用于 JS/TS:
web3py
from web3 import Web3
# Set up HTTPProvider
w3 = Web3(Web3.HTTPProvider('http://localhost:8545'))
# API
w3.eth.get_balance('0xaddress')
ethers.js
import { ethers } from "ethers";
const provider = new ethers.providers.JsonRpcProvider("http://localhost:8545");
await provider.getBlockNumber();
通常,所有的 web3 库都会封装 JSON-RPC 方法,提供一种更友好的方式与执行层进行交互。可以根据偏好的编程语言查看相关信息,因为不同语言的语法可能会有所不同。
进一步阅读
- Ethereum JSON-RPC Specification
- Execution API Specification
- JSON-RPC | Infura docs
- reth book | JSON-RPC
- OpenRPC
递归长度前缀(RLP)序列化
递归长度前缀(RLP)是以太坊执行层中用于编码和解析数据的核心序列化协议。它旨在序列化数据并生成所有客户端软件都可读的结构。它用于从交易数据到区块链的整个状态的所有内容。本维基页面探讨了 RLP 的内部原理、其编码/解码规则、可用工具以及它在以太坊功能中的作用。
以太坊中的数据序列化
数据序列化是将数据结构或对象转换为字节流以进行存储、传输或后续重建的过程。在以太坊这样的分布式系统中,序列化对于在网络节点之间可靠且高效地传输数据至关重要。用不同语言编写的客户端需要能够以相同的方式处理数据。传输给其他节点或由客户端导出的数据需要有标准格式。虽然有像 JSON、XML 或 Protobuf 这样常见的序列化格式,但以太坊使用其自己的协议,因为它在编码嵌套字节数组方面简单且有效。
以太坊实际上使用两种格式:RLP 和简单序列化(SSZ),后者是共识层使用的更现代的标准。
RLP 算法的工作原理
RLP 编码算法
以下是 RLP 编码算法的流程图。
注意:在某些 RLP 工具中,一些客户端可能会添加额外的条件情况到流程中。这些额外的条件情况不是标准规范的一部分,但它们对于客户端正确序列化数据非常有用,例如 geth 客户端节点与 Nethermind 客户端节点通信时。
flowchart TD
A[Start: Input] --> B{Is Input null, empty string, or false?}
B -->|Yes| C[Encode as Single Byte 0x80]
B -->|No| D{Is it a Single Byte and < 0x80?}
D -->|Yes| E[Directly Encode the Byte]
D -->|No| F{Is it a String or List?}
F -->|String| G{String Length <= 55}
G -->|Yes| H[Encode with Length + 0x80]
G -->|No| I[Encode Length with 0xB7 + Length Bytes]
F -->|List| J{Total Encoded Items Length <= 55}
J -->|Yes| K[Encode with Total Length + 0xC0]
J -->|No| L[Encode Total Length with 0xF7 + Length Bytes]
H --> M[Output Encoded Data]
I --> M
K --> M
L --> M
E --> M
C --> M
Figure: RLP Encoding Flow
RLP decoding algorithm
以下流程图描述了 RLP 解码算法的工作原理。
flowchart TD
A[Start: Encoded Input] --> B{Check First Byte}
B -->|0x00 to 0x7F| C[Direct Byte Output]
B -->|0x80| D[Decode as Empty String/Null/False]
B -->|0x81 to 0xB7| E[Short String]
E --> F[Subtract 0x80 from First Byte to get Length]
F --> G[Output Next 'Length' Bytes as String]
B -->|0xB8 to 0xBF| H[Long String]
H --> I[Subtract 0xB7 from First Byte to get Length Bytes Count]
I --> J[Read Next 'Length Bytes Count' to Determine String Length]
J --> K[Output Next 'String Length' Bytes as String]
B -->|0xC0 to 0xF7| L[Short List]
L --> M[Subtract 0xC0 from First Byte to get Total Encoded Length]
M --> N[Decode Each Element in the Next 'Total Encoded Length' Bytes Recursively]
B -->|0xF8 to 0xFF| O[Long List]
O --> P[Subtract 0xF7 from First Byte to get Length Bytes Count]
P --> Q[Read Next 'Length Bytes Count' to Determine List Total Length]
Q --> R[Decode Each Element in the Next 'List Total Length' Bytes Recursively]
C --> S[Output Decoded Data]
D --> S
G --> S
K --> S
N --> S
R --> S
Figure: RLP Decoding Flow
RLP 编码规则
理解 RLP 编码的推导需要掌握基于数据类型和大小应用的具体规则。让我们通过示例来探索这些规则,展示不同类型数据是如何编码的。
如果你不熟悉字符串转十六进制的过程,可以参考这个 ASCII 对照表。
RLP 编码规则的详细说明和示例
递归长度前缀(RLP)是以太坊中用于将结构化数据编码为字节序列的基础数据序列化技术。理解 RLP 编码的推导需要掌握基于数据类型和大小应用的具体规则。让我们逐步通过示例来探索这些规则,展示不同类型数据是如何编码的。
单字节编码
- 条件: 如果输入是单个字节且其值在
0x00和0x7F之间(包含边界)。 - 编码: 该字节直接编码,保持不变。
- 示例: 编码字节
0x2a直接得到0x2a。
短字符串编码(1-55 字节)
- 条件: 如果字符串(或字节数组)长度在 1 到 55 字节之间。
- 编码: 输出为字符串长度加上
0x80,后跟字符串本身。 - 示例: 编码字符串 "dog" (
0x64, 0x6f, 0x67) 得到0x83, 0x64, 0x6f, 0x67。这里0x83是0x80 + 3("dog" 的长度)。
长字符串编码(超过 55 字节)
- 条件: 如果字符串长度超过 55 字节。
- 编码: 字符串的长度被编码为大端格式的字节数组,前缀为
0xb7加上这个长度数组的长度。 - 示例: 对于长度为 56 的字符串,长度
0x38被编码,前面加上0xb8(0xb7 + 1)。最终编码以0xb8, 0x38开始,后跟字符串的字节。
短列表编码(总负载 1-55 字节)
- 条件: 如果列表项的总编码负载在 1 到 55 字节之间。
- 编码: 列表前缀为
0xc0加上编码项的总长度。 - 示例: 对于列表
["cat", "dog"],每个项先编码为0x83, 0x63, 0x61, 0x74和0x83, 0x64, 0x6f, 0x67。总长度为 8,所以前缀是0xc8(0xc0 + 8 = 0xc8)。完整编码为0xc8, 0x83, 0x63, 0x61, 0x74, 0x83, 0x64, 0x6f, 0x67。
长列表编码(总负载超过 55 字节)
- 条件: 如果列表项的总编码负载超过 55 字节。
- 编码: 类似于长字符串,负载的长度以大端格式编码,前缀为
0xf7加上这个长度数组的长度。 - 示例: 对于超过 55 字节的列表
["apple", "bread", ...],假设负载长度为 57。长度0x39被编码,前面加上0xf8(0xf7 + 1),后跟编码的列表项。
空值、空字符串、空列表和 false
- 空字符串、空值和 false 的规则: 编码为单个字节
0x80。 - 空列表的规则: 编码为
0xc0。 - 示例:
- 编码空字符串、空值或 false (
null,false) 得到0x80。 - 编码空列表
[]得到0xc0。
- 编码空字符串、空值或 false (
RLP 解码规则
RLP 解码过程基于编码数据的结构和具体特征:
确定数据类型:
- 编码数据的第一个字节(前缀)决定了后续数据的类型和长度。这个字节对指导解码过程至关重要。 解码单字节:
- 如果前缀字节在
0x00到0x7F范围内,该字节本身就代表解码后的数据。这种情况很简单,因为字节是直接编码的。 解码字符串和列表: - 解码的复杂性主要来自于字符串和列表,它们具有不同的长度并可能包含嵌套结构。 短字符串(0x80 到 0xB7):
- 如果前缀字节在
0x80和0xB7之间,表示这是一个字符串,其长度可以通过从前缀中减去0x80直接得到。后续等于该长度的字节就是字符串内容。 长字符串(0xB8 到 0xBF): - 对于较长的字符串,如果前缀字节在
0xB8和0xBF之间,长度字节的数量可以通过从前缀中减去0xB7得到。随后的字节表示字符串的长度,之后的字节则是字符串本身。 短列表(0xC0 到 0xF7): - 类似于短字符串,前缀在
0xC0和0xF7之间表示这是一个列表。列表编码数据的长度可以通过从前缀中减去0xC0得到。随后的字节必须递归解码为单独的 RLP 编码项。 长列表(0xF8 到 0xFF): - 对于较长的列表,前缀在
0xF8和0xFF之间表示接下来的几个字节(通过从前缀中减去0xF7确定)将告诉我们列表编码数据的长度。这些长度字节之后的数据然后被递归解码成 RLP 项。
RLP 解码示例 [0xc8, 0x83, 0x63, 0x61, 0x74, 0x83, 0x64, 0x6f, 0x67]
- 识别前缀
- 序列以字节
0xc8开始。在 RLP 中,列表的长度前缀从0xc0开始。0xc8和0xc0的差值给出了列表内容的长度。0xc8 - 0xc0 = 8
- 这告诉我们接下来的 8 个字节是列表的一部分。
- 序列以字节
- 解码列表内容
- 本例中的列表内容是
[0x83, 0x63, 0x61, 0x74, 0x83, 0x64, 0x6f, 0x67]。 - 我们将逐字节解码这些内容以提取各个项。
- 本例中的列表内容是
- 解码第一项
- 列表内容的第一个字节是
0x83。在 RLP 中,对于长度在 1 到 55 字节之间的字符串,长度前缀从0x80开始。因此:0x83 - 0x80 = 3
- 这表明第一个字符串的长度为
3字节。 - 接下来的三个字节是
0x63, 0x61, 0x74,对应 ASCII 值为 "cat"。 - 现在我们已经解码出第一项: "cat"。
- 列表内容的第一个字节是
- 解码第二项
- 解码第一项后,序列中的下一个字节是另一个
0x83。 - 按照相同的规则:
0x83 - 0x80 = 3
- 这表明下一个字符串也有 3 个字节长。
- 接下来的三个字节是
0x64, 0x6f, 0x67,对应 "dog"。 - 现在我们已经解码出第二项: "dog"。
- 解码第一项后,序列中的下一个字节是另一个
- 解码后的输出是
["cat", "dog"]。
以太坊为什么需要 RLP
RLP 旨在成为一个高度简约的序列化格式;它的唯一目的是存储嵌套的字节数组。与 protobuf、BSON 和其他现有解决方案不同,RLP 不试图定义任何特定的数据类型,如布尔值、浮点数、双精度数或甚至整数;相反,它仅仅用于以嵌套数组的形式存储结构,并将数组的含义解释权留给协议。 -- 以太坊设计理念
RLP 是为以太坊创建的,专门用于满足其特定需求:
- 极简设计:它纯粹专注于存储结构,而不强加数据类型定义。
- 一致性:它保证了不同实现之间的字节级一致性,这对区块链操作所需的确定性特征至关重要。
RLP 工具
以太坊中有许多可用的 RLP 实现库。以下是一些工具:
- Geth RLP
- RLP Dump
- RLP for Node.js and the browser.
- Python RLP serialization library.
- RLP for Rust
- Nethermind RLP Serialization
Resources
- Ethereum Yellow Paper
- Ethereum RLP documentation
- A Comprehensive Guide to RLP Encoding in Ethereum by Mark Odayan
- Ethereum's RLP serialization in Elixir
- Ethereum Under The Hood Part 3 (RLP Decoding)
- Ethereum's Recursive Length Prefix in ACL2
区块构建
介绍
区块构建是以太坊区块链功能中的关键任务,涉及多个流程,这些流程决定了验证者如何获取区块并进行提议。
以太坊网络由运行互联共识客户端(CL)和执行客户端(EL)的节点组成,这两者对参与网络和在每个时间槽中生成区块都是不可或缺的。
执行客户端(EL)具有许多重要功能,你可以通过学习 el-architecture 来深入了解, 本文的重点是介绍其为共识客户端(CL)构建区块的角色。
当一个验证者在某个 Slot 时间槽中被选中提议出块时,它会寻找由共识客户端(CL)生成的区块。值得注意的是,验证者并不限于广播自己 EL 生成的区块,也可以广播由外部构建者生成的区块;详情请参阅 PBS。
本文特别探讨了 执行客户端(EL)如何生成区块,以及哪些要素影响着区块的成功生成和交易执行。
Payload 构建流程
译者注:
在以太坊中,Payload 通常是指由执行层(EL)生成的区块数据,包含了区块中的所有重要信息,如交易数据、状态根(state root)、交易根(transaction root)、收据根(receipts root)等,用于确保区块的有效性和完整性,会被传递到共识层(CL)进行验证和传播
当共识层通过 engine API's fork choice updated 端点指示执行层客户端时,区块就被创建了,然后通过 payload building routine 启动区块构建过程。
译者注:
在以太坊中,共识层(CL)通过分叉选择规则(fork choice rule) 来决定在存在多个区块链(或分叉)时,哪条链被认为是有效链的逻辑,尤其是在网络分裂或同时产生多个区块的情况下。
engine API's fork choice updated端点 是指以太坊协议中的一个特定 API 端点,允许执行层(EL)做出决定,选择哪条分叉链应该被视为有效链。当一个验证者被选中提议区块时,通过 engine API 调用 fork choice updated 端点,通知执行层当前的最佳链。这一操作有助于决定接下来应该构建哪一个区块,确保执行层在正确的链分支上工作,并根据这个分支构建新的区块
注: 费用接收者可能与预期的接收者不同,在正常情况下,区块中规定了一个建议的费用接收者地址,但在某些情况下,实际构建区块时,所选定的费用接收者地址可能与建议的地址不同。例如,如果某个外部构建者(external builder)参与了区块的构建过程,他们可能会选择将费用发送给其他地址,而不是建议的接收者地址

节点通过 P2P 点对点网络传播交易。这些交易被认为是有效的,但尚未被包含在区块中。 交易的有效性主要指以下条件:交易的 nonce 是账户的下一个有效 nonce,并且账户拥有足够的余额来覆盖交易费用。
有时,节点会被分配到生成区块的任务。共识层通过随机选择过程来确定每个 epoch 中哪个验证者来负责构建区块。
如果你的验证者被选中构建区块,你的共识层客户端将使用执行引擎的 fork choice updated 方法进行构建,并提供区块构建所需的上下文。
我们可以简化并模拟区块构建的过程,使用 Go 语言来完成一个简单的特定实现:
func build(env environment, pool txpool.Pool, state state.StateDB) (types.Block, state.StateDB) {
var (
gasUsed = 0
txs []types.Transactions
)
for ; gasUsed < 30_000_000 || !pool.Empty(); {
transaction := pool.Pop()
res, gas, err := vm.Run(env, transaction, state)
if err != nil {
// transaction invalid
continue
}
gasUsed += gas
transactions = append(transactions, transaction)
}
return core.Finalize(env, transactions, state)
}
-
接收 3 个传参变量
env environment包含环境所有必要信息,包括时间戳、区块编号、前置区块、基础费用以及需要在区块中发生的所有提取操作, 这些信息本质上来源于共识层。- 交易池
txpool.Pool变量,即交易的集合,为简单起见,我们假设这些交易按其价值升序排列,价值越高的交易更容易被确认打包 state.StateDB状态数据库表示执行这些交易的状态存储
最后生成并返回以下内容:
- 一个完整的区块
- 一个包含所有交易的状态数据库(state DB),它记录了所有交易的执行结果和更新后的状态
- 如果在处理过程中出现了错误,还可能会返回一个错误信息
-
在 build 函数中,我们跟踪 gas 消耗
gasUsed,因为我们可以使用的 gas 是有限的。我们还存储所有将被包含在区块中的交易。 -
我们继续添加交易,直到交易池为空,或者消耗的 gas 超过 gas 限制。为了简单起见,在这个例子中,gas 限制设定为 3000 万(大约是主网当前的 gas 限制)。
-
为了获取一笔交易,我们必须查询交易池,假设交易池会维护一个有序的交易列表,确保我们始终获取到下一个最有价值的交易。
-
交易在 EVM 中执行,在执行交易时,系统将交易、环境和当前状态作为输入,并在这些输入条件下执行交易。交易的执行会根据当前环境(如区块链状态)进行,并在执行过程中更新状态数据库,包括所有已成功执行的交易
-
如果交易执行失败,并且在执行过程中发生错误,我们将继续处理下一笔交易,而不立即中断。这表明该交易无效,并且由于区块中仍有未使用的 gas,我们不希望立即生成错误。因为在区块中尚未发生错误,因此我们可以继续进行处理。然而,很可能该交易是无效的,因为它在执行过程中发生了错误,或者交易池中的数据略有过时。在这种情况下,我们允许继续并尝试从交易池中获取下一笔交易,继续将其加入到当前区块中。
-
一旦我们验证运行交易没有错误,我们就会将该交易添加到交易列表中,并将运行返回的气体添加到所使用的气体中。例如,如果第一笔交易是简单的转账,需要花费 21,000 Gas,那么我们使用的 Gas 将从 0 到 21,000,我们将继续执行此过程步骤 3-7,直到满足步骤 3 的条件
-
我们通过获取一组交易和相关区块信息, 以最终确定生成一个完整的区块, 这样做的目的是为了最后进行一定的计算。由于 header 包含交易根、收据根和提款根,因此必须通过默克尔化列表来计算这些值并将其添加到块的 header 中
代码走读
Geth
以下示例使用 Geth 的代码库来解释执行客户端如何构建区块。
-
首先,当一个验证者被选中作为区块构建者时,它通过执行层(EL)的 Engine API 调用
engine_forkchoiceUpdatedV2函数。此时,执行层启动区块构建过程 -
区块构建的大部分核心逻辑和交易执行都在 Geth 的
miner模块中。buildPayload函数最初会创建一个空区块,这样节点就不会错过时间槽,并且有东西可以提议。函数的实现还会启动一个 go 协程,其任务是填充该空区块,然后将填充的交易并发更新到区块中 -
在
buildPayload函数中,go 协程正在等待多个通信操作的“case”。在第一个 case 中,它调用getSealingBlock函数,并显式指定区块不应为空(参数为noTxs:False) -
在
getSealingBlock的定义中,请求被发送到getWorkCh通道。这个通道正在被监听,用于从中检索数据并生成工作任务 -
getWorkCh通道正在同一文件中的mainLoop函数内被监听。从getWorkCh通道接收到的数据会发送到w.generateWork函数 -
generateWork函数是将交易填充到区块中的地方 -
w.fillTransactions函数从内存池(mempool)中检索所有待处理交易并填充到区块中。这包括所有类型的交易,包括blobs -
交易按其费用排序后填充,并传递给
commitTransactions函数 -
commitTransactions函数检查每笔交易是否有足够的 gas 可以使用,然后提交该交易。此外,每个区块允许的blobs数量由EIP-4844规定 -
如果查看
commitTransaction函数,会发现它会回调w.applyTransaction函数 - https://github.com/ethereum/go-ethereum/blob/0a2f33946b95989e8ce36e72a88138adceab6a23/miner/worker.go#L760C18-L760C36 -
applyTransaction函数进一步调用核心包中的core.ApplyTransaction,该函数会根据本地执行层状态执行所有交易 -
ApplyTransaction函数会在本地执行层状态中运行交易并进行所有状态更改。它会创建 EVM 上下文和环境以在 EVM 中执行交易。合约调用也在这里完成。如果一切顺利,状态将成功地发生转换 -
当然交易也可能失败,如果交易失败,状态则不会转换。失败的原因可能包括链上原因,例如 gas 耗尽、合约调用失败等。
-
从这一点开始,所有交易会逐一执行。交易随后被打包到区块中。
-
然后,共识层通过 Engine API 请求执行层,获取填充了交易的有效
payload。执行层将此payload返回给共识层,后者将此payload放入信标区块并传播它
引用资源
共识层概述
共识协议的主要目标是在不可靠的基础设施上构建一个可靠的分布式系统。对共识协议的研究可以追溯到 20 世纪 70 年代,但以太坊试图实现的目标远比之前的研究更具野心。
在以太坊的共识层中,目标是确保全球成千上万的独立节点保持合理同步。每个节点都维护着包含所有账户状态的账本,这些账本必须完全一致,不允许有任何差异,节点之间必须快速达成一致,这也就是我们所说的“可靠的分布式系统”。
这些节点通常使用消费级硬件并通过可能速度较慢、丢失数据或意外断开连接的互联网通信。节点操作员可能会错误配置软件或未能及时更新。此外,可能有许多恶意参与者运行伪造节点或篡改通信以谋取私利。这就是我们所说的“不可靠的基础设施”。
拜占庭容错(BFT)和拜占庭将军问题
拜占庭容错(Byzantine Fault Tolerance, BFT)是分布式系统的一种特性,它允许分布式系统在某些组件发生故障或恶意行为时仍能正常。运行BFT 在去中心化网络中尤为重要,因为这些网络中的节点之间无法假设存在信任关系。换句话说,具备 BFT 的系统可以容忍拜占庭故障,即包括恶意行为在内的任意故障。为了实现拜占庭容错,系统必须在存在这些故障的情况下达成共识。关于这个问题及其实际解决方案的更多信息,请参阅这里。
共识层简介
共识是一种利用不可靠组件构建可靠分布式系统的方法。基于区块链的分布式系统旨在就一系列交易的单一历史达成一致。
工作量证明(Proof-of-work)和权益证明(Proof-of-stake)并不是共识协议,而是使共识协议成为可能的机制。在以太坊中,节点和验证者是共识系统的执行者。slots 和 epochs 调控共识的时间, 区块和证明是达成共识的价值媒介
共识层是确保网络安全性、可靠性和效率的基础组件。最初,以太坊采用类似比特币的工作量证明(Proof-of-work, PoW)作为共识机制。虽然 PoW 在保持去中心化和安全性方面非常有效,但也有着显著缺点,比如其高能耗和有限的可扩展性。为了解决这些问题,以太坊已转向更可持续和可扩展的权益证明(Proof-of-stake, PoS)机制。
以太坊网络由许多独立节点组成,每个节点独立运行,通过互联网进行通信,而互联网往往不可靠并且是异步的
用户将交易发送到这些节点组成的网络,共识协议确保所有诚实的节点最终达成唯一且一致的交易历史,这意味着它们会就交易的顺序及其结果达成一致。例如,如果我有 1 ETH,并同时告诉网络将其发送给 Alice 和 Bob,网络最终必须决定我到底将其发送给了 Alice 还是 Bob。如果 Alice 和 Bob 都收到了这笔 Ether,或者两者都未收到,那将是失败的。共识协议就是促成交易顺序上达成一致的过程
以太坊的共识协议实际上结合了两种不同的共识协议。一个被称为 LMD GHOST,另一个是 Casper FFG。两者的结合被称为 Gasper。在后续部分中,我们将分别和结合地探讨它们。
工作量证明与权益证明
在这里需要澄清,工作量证明(PoW)和权益证明(PoS)本身并不是共识协议。它们通常被错误地这样称呼,但实际上它们是使共识协议成为可能的机制。PoW 和 PoS 的主要作用是作为 Sybil 攻击的抗性机制,为参与协议设置成本代价,从而防止攻击者以低成本压垮系统。
PoW 和 PoS 都是通过分叉选择规则与它们支持的共识机制紧密相连。它们帮助为区块链分支分配权重或评分:在 PoW 中,是完成的计算总工作量;在 PoS 中,这是支持特定链的总抵押价值。在这些基本原理之上,PoW 和 PoS 可以支持各种共识协议,每种协议都有其自身的动态和权衡。
区块链概述
区块是区块链的基本构成单位, 一个区块是由领导者(区块提议者)组装的一组交易组成,区块的具体内容会依据协议的不同而有所变化。
- 在以太坊执行链上,区块的有效负载是用户交易的列表
- 在合并前的 PoS 信标链上,区块的有效负载主要由区块验证者的一系列证明组成
- 合并后的信标链区块同时包含执行的有效负载(用户的交易集合)。
- 自 EIP-4844(Deneb 升级)后,区块还包含了不透明数据 blob 的承诺。
除了创世区块,每个区块都建立在父区块之上并指向父区块,形成一个区块链。网络中的所有节点的目标是对相同的规范区块链历史达成一致。

时间从左向右推进,除了创世区块,每个区块都指向其构建的父区块
链随着节点向其末端添加新块而增长, 这是通过暂时选择一个“领导者”(延长链条的节点)来实现的。在 PoW 中,领导者是第一个为其区块解决 PoW 难题的矿工。在以太坊的 PoS 中,提议者(领导者)是从活跃验证者集中伪随机选出的。
领导者(区块提议者)将区块添加到链中,选择并排序其内容。区块必须符合协议规则,否则网络将忽略它。使用区块是一种优化。如果逐一添加交易,将产生巨大的共识开销。因此,区块是交易的批处理。在以太坊执行链中,区块大小受区块 gas (处理交易所需的费用)限制。信标区块大小则受硬编码常量限制。
过渡到权益证明
2022 年 9 月 15 日,以太坊完成了从工作量证明(PoW)到权益证明(PoS)的转变,这一新机制被称为共识层,也就是被称为以太坊 2.0 的信标链。
以太坊的巴黎硬分叉(合并)基于“终端总难度”(TTD)而非区块高度激活,以避免恶意分叉等风险。这确保了 PoS 转变仅在累计难度达到关键阈值时发生。终端区块是最后一个 PoW 区块,其总难度超过预定义阈值,从而确保安全性。总难度是递归计算得出的,反映了区块链中的计算工作量。
这一点至关重要,因为测试网、开发网以及任何运行最新软件的以太坊网络都需要通过总终端难度(TTD)而非区块高度来激活合并。更多细节请参考过渡标准和总终端难度
译者注: TTD 是以太坊网络中计算出的一个阈值,它表示区块链中累计计算难度的总和, 当某个区块的总难度达到或超过这个阈值时,就触发权益证明的激活。
为什么使用 TTD 而不是区块高度:
- 安全性:区块高度是一个简单的计数器,但容易受到攻击者通过快速生成低质量区块(恶意分叉)的操控。
- 动态性:总难度反映了实际的计算工作量,能够更好地适应 PoW 网络中的计算波动,确保过渡时机更加自然和安全
合并引入了以下变化:
- 信标链接管:信标链, 已与以太坊主网并行运行,接管了处理新区块的责任。在 PoS 中,区块由抵押 ETH 的验证者验证,而非通过矿工解决密码学难题。
- 安全性和效率:此转变不仅旨在通过去中心化增强以太坊网络的安全性,还显著减少了能源消耗,解决了这一关于传统工作量证明(PoW)系统的主要批评
- 新的共识机制:在权益证明(PoS)机制下,共识的达成依赖于质押、验证者的证明以及随机选择区块提议者和委员会的算法相结合,以此确保网络的安全性并高效处理交易。
信标链简介
信标链在 PoS 共识管理中起着关键作用。它监管着提出新区块并对其进行验证的验证者,确保网络的完整性与安全性。验证者的选择基于多个标准,其中之一是他们抵押的 ETH 数量,这也作为防止不诚实行为的担保。
验证者的主要职责包括:
- 抵押 ETH:验证者必须抵押至少 32 ETH 才能参与。
- 提议区块:随机选中的验证者负责提议新区块,必须构建有效区块并将其广播至网络。
- 区块认证:验证者对其他人提议的区块的有效性进行认证。这些认证本质上是对区块有效性的投票,确保共识。
- 参与共识:通过定期投票帮助最终确定区块链状态。
巴黎硬分叉是以太坊历史上的一个关键事件,为更可扩展、可持续和安全的操作奠定了基础。它代表了以太坊对创新的承诺,以及其对加密货币挖矿环境影响这一更广泛社会关切的积极响应
信标链及其基础
信标链是以太坊共识机制的核心支柱。它负责协调验证者、管理权益证明(PoS)协议,并确保整个网络达成共识。本节将深入剖析信标链的构成与运作原理
验证者
验证者本质上是PoS协议中的参与者。他们负责提议和验证新区块,确保区块链的完整性与安全性。验证者需质押ETH作为抵押,以此将其利益与网络的健康状况绑定。验证者被选中提议区块,基于以下因素:
- 抵押 ETH:每个验证者最多可抵押 32 ETH,拥有更多以太币(ETH)的质押者可以通过运行多个验证节点来增强其影响力,每个节点需质押32 ETH。这一机制确保了网络的去中心化,并使验证者的利益与网络的安全性和完整性保持一致
- 随机性:选择选拔过程融入了加密随机性,以防止可预测性和操纵行为。这一目标通过RANDAO 和 VDF(可验证延迟函数)机制得以实现
- 委员会:验证者被分组为委员会,负责区块提议和验证工作。每个委员会的任务是验证并对区块进行确认,以此保障去中心化且安全的验证流程
- 质押要求: 要成为验证者,个人需向官方存款合约存入至少32个以太币(ETH)。这些ETH作为抵押,旨在激励诚实行为。若验证者未能履行职责或参与恶意活动,其 ETH 将面临被扣除的风险
Slots 与 Epochs
每个 slot 为12秒,一个 Epoch 包含 32 个 slot,合计384秒或6.4分钟。每个 slot 都分配有验证者来提议一个区块,而由验证者组成的委员会则负责确认该区块的有效性
一个 slot 代表在信标链上添加一个区块的机会,每12秒便有一个区块被添加。
译者注: 如果提议者因为节点离线,网络延迟等原因未能按时完成区块提议或者提议者的行为被视为无效,即无效区块,可能会导致该 slot 空置
验证者需要与时间同步。slot类似于区块时间,但slot可能为空(未添加区块)。信标链的创世区块位于时隙0

第一个 32 个slot属于第 0 epoch. 信标链的创世区块位于第 0 slot,
验证者与证明
区块提议者是被伪随机选中的验证者,负责构建区块。验证者们不仅提出区块,还对他人提出的区块进行认证。大多数时候,验证者扮演着投票者的角色,对区块进行表决。这些投票记录在信标链上,并决定了信标链的头部位置
证明是对区块有效性的投票,这些投票被汇总到信标链中以确保共识。

如图所示,在第28个slot处,可能会出现slot为空的情况
每个证明都是是一个验证者的投票,其权重取决于验证者的质押量。除了区块外,验证者还会广播这些证明。验证者之间相互监督,对于举报那些做出矛盾投票或提议多个区块的其他验证者,会获得奖励
信标链的内容主要包括验证者地址的注册表、每个验证者的状态以及证明。验证者由信标链激活,并能转换至不同状态。
关于质押验证者语义的重要说明:在以太坊的权益证明(PoS)机制中,用户通过质押ETH来激活验证者,这类似于在工作量证明(PoW)中购买硬件设备。质押者与其质押的ETH数量相关联,而每个验证者的最大余额为32 ETH。每质押32 ETH,即可激活一个验证者。验证者由验证者客户端运行,这些客户端通过信标节点来跟踪并读取信标链。一个验证者客户端能够管理多个验证者
委员会
委员会是在每个slot时,由至少128名被分配验证者组成的群体,用以加强安全性。攻击者控制委员会三分之二成员的概率低于万亿分之一。
随机信标的概念,即向公众发布随机数的机制,正是信标链得名的由来。信标链通过一个名为RANDAO的伪随机过程来强制执行共识

每个 epoch,一个伪随机过程RANDAO会为每个slot(slot)选择提案者,并将验证者分配到各个委员会中.
验证者的选择:
- 如上所述,验证者由RANDAO选出,其权重依据验证者的余额而定
- 验证者可能同时担任提案者和委员会成员,但这种情况较为罕见(概率为1/32)
下图描绘了验证者数量少于 8192 个的情形,否则每个slot 至少会有两个委员会

- slot1:一个区块被提出并由两位验证者确认;其中一位验证者离线。
- slot2:一个区块被提出,但一位验证者错过了,去确认了前一个区块。
- slot3:遵循LMD GHOST规则,委员会C中的所有验证者都确认了同一个头部区块。
验证者通过LMD GHOST规则对Beacon Chain的头部视图进行认证。认证通过就区块链状态达成共识,有助于区块的最终确认
委员会规模与安全性:
- 拥有超过 8192 个验证者时,每个 slot 会形成多个委员会。
- 为了达到最佳安全性,每个委员会至少需要128名验证者。
- 当验证者数量少于 4096 时,由于委员会规模降至128以下,安全性会随之降低
在每个 epoch,验证者被均匀分配到各个 slot,并进一步细分为大小适宜的委员会。该 slot 内的所有验证者都对信标链的头部进行认证。一种洗牌算法会根据需求调整每个 slot 的委员会数量,确保每个委员会至少有128名验证者。关于洗牌算法的更多细节,可在proto 代码库中找到
Blobs
EIP-4844,又称proto-danksharding,是Deneb/Cancun硬分叉的一部分。它为以太坊引入了数据可用性层,使得在区块链上临时存储任意数据成为可能。以这种方式存储的任意数据被称为 blob,每个区块可包含3 至 6个 blob sidecars(即blob的封装)。EIP-4844标志着以太坊迈向分片和可扩展性的第一步,使第二层解决方案(L2s)能够利用这一数据可用性层来降低 gas 费用并处理更多交易
设计与实现
EIP-4844中的一项关键设计决策是采用 KZG 承诺 来验证数据块(blobs)并支持未来提议者与构建者的分离。为了使用KZG承诺,需要一个可信设置(Trusted Setup)。针对Deneb硬分叉,通过实施 KZG Ceremony 以创建这一可信设置。

存储要求
对节点运营商最显著的影响是存储需求的增加。节点运行者将需要更多的存储空间:
131,928 ssz bytes per blob * 4096 blobs retention period *
32 potential blocks per epoch * 3~6 blob sidecars per block
= 52~104GB
默认情况下,这些数据块将保留4096个 epoch,一旦达到保留期限,客户端将删除最旧的数据块。
检查点与最终确认
每个 epoch 结束时,都会创建检查点。检查点是该 epoch 第一个 slot 中的区块。若该slot无区块,则检查点为之前最近的一个区块。每个 epoch 总有一个检查点区块,而一个区块可能成为多个 epoch 的检查点

包含 64个 slots 的 epoch 场景下的检查点
如上图所示,若第65至128号 slot 为空,则 epoch 2 的检查点默认指向第64 号 slot的区块。同理,若第192 号slot 空缺,epoch 3 的检查点即为第 180 号 slot 的区块。Epoch 边界区块(EBB)是部分文献(如上述图表来源及后续提及的 Gasper 论文)中的术语,它们可视为检查点的同义词
验证者进行两种类型的投票:LMD GHOST 投票针对区块,Casper FFG 投票针对检查点。一次 FFG 投票包含来自前一个 Epoch 的一个源检查点和当前 Epoch 的一个目标检查点。例如,Epoch 1 的验证者可能投票支持创世区块作为源检查点,以及第64个 slot 作为目标检查点,并在Epoch 2 重复相同的投票。只有被分配到特定 slot 的验证者才会进行 LMD GHOST 投票,而所有验证者都会对 epoch 检查点进行FFG投票
绝对多数(Supermajority )和最终确认
要使一个检查点得到验证,需要获得绝对多数支持,即三分之二以上的验证者支持。例如,若验证者的余额分别为 8 ETH、8 ETH和32 ETH,那么绝对多数就意味着需要 32 ETH验证者的投票支持。一旦某个检查点获得绝对多数支持,它便被视为已证明。若后续 epoch 的检查点同样获得证明,前一个检查点则被最终确认,从而确保所有之前区块的安全。通常,这一过程跨越两个 Epoch(12.8分钟)。
当用户交易被打包进一个区块时,平均而言,它大约位于一个 epoch 的中间位置。到达下一个检查点需要半个 epoch,约3.2分钟,这意味着交易最终确认需要2.5个 epoch,即16分钟。理想情况下,超过三分之二的验证会在一个 epoch 的第22个(32的三分之二)slot 内完成。因此,交易的最终确认需要平均为14分钟(16+32+22个 slots)。
区块确认过程始于区块的验证证明,随后推进至其合理性验证,最终达到不可逆的最终确认。具体应用场景可自行决定是否需要最终确认,还是更早的安全阈值就已足够。

示例:一个检查点(slot 64)被证明合理,并最终确定了前一个检查点(slot 32)
信标链头发生的情况:在 slot 96,提出了一个包含对 Epoch2 的检查点认证(投票)的区块,当认证达到了所需的三分之二绝对多数时,Epoch2 检查点的合理性也就被确认了。这一操作最终确定了之前已验证的 Epoch 1 检查点。当 Epoch 1检查点被最终确认时,所有之前的区块(直至 slot 32)也随之被最终确认。最终确认发生在 Epoch 边界,但认证会随着每个区块的提出而累加。
从创始区块到信标链头可能发生的情况:
- 场景 1:
- 从Slot 1到Slot 63的提议者提出区块。
- Epoch 1中的每个区块都为Slot 32的检查点提供证明,最终达到55%。
- Slot 64的区块包含额外的证明,使对Slot 32检查点的支持率达到70%,从而使其得到验证。
- 在整个Epoch 2期间,Slot 64的检查点收集证明,但直到Slot 96才达到三分之二的门槛,此时它被验证。
- 验证Epoch 2的检查点会最终确定Epoch 1的检查点及之前的所有区块
- 场景 2:
- Epoch 1 的检查点有望在到达下一 Epoch 前达到三分之二以上的绝对多数支持。
- 例如,从第32 slot 到第 54 slot (2/3 epoch ~= 22 个 slot)的区块能够提供足够的证明,使第32 slot 的检查点得以验证。这样一来,第32 slot 的检查点将在当前 Epoch 内得到验证,但仍需到下一 Epoch 才能最终确认
特殊情况:检查点的合理性有时可以确认两个或更多 epoch 前的区块,尤其是在高延迟、网络分区或遭受攻击期间。你可以在Gasper论文中找到更多此类案例的讨论。这些情况属于例外,并非常态
深入探究认证机制
验证者每个 epoch 提交一次证明,包含 LMD GHOST 和 FFG投票结果。这些证明每个 epoch 期间有 32 次被打包记录到链上的机会,越早上链奖励越高。这意味着一个验证者在一个 epoch 内可能有两个证明被纳入链上。当验证者的证明在其指定时段被记录到链上时,他们获得的奖励最多;之后的奖励会递减。为了让验证者有准备时间,他们会提前一个 epoch 被分配到委员会中。与验证者不同,区块提议者(proposers)只有在 Epoch 开始后,才会被分配到特定的 Slot。在此之外,也有秘密领导者选举研究旨在减轻对提议者的攻击或贿赂
假设在Slot 64提出的一个区块,其中包含对Epoch 2检查点的证明。这种情况下,第32个 slot 的检查点可以被最终确认。一旦Slot 32 检查点的最终性得以实现,这种确定性将向后传播,确保所有先前区块的安全性。
本质上,委员会其实允许将每个证明者的签名技术性地优化组合成一个单一的聚合签名。当同一委员会中的验证者做出相同的LMD GHOST和FFG投票时,他们的签名可以被聚合起来。
质押奖励与惩罚
以太坊的权益证明(PoS)系统采用了一套全面的奖励与惩罚机制,以激励验证者行为并维护网络安全。本节将探讨这些激励措施的六大关键方面:
- 验证者奖励:验证者因做出与大多数其他验证者一致的见证(LMD GHOST和FFG投票)而获得奖励。被打包进最终确认区块的见证更具价值
- 验证者惩罚机制:验证者若未能进行证明或对提交的见证支持了未被最终确认(finalized)的区块,将受到惩罚。这些惩罚措施旨在确保验证者保持活跃状态,并与网络的共识保持一致
译者注:
惩罚的具体机制
离线罚款(inactivity leak):验证者长时间离线或未能提交见证,将持续被扣罚质押 ETH。在极端情况下,如果离线验证者的数量较多,网络会进入 inactivity leak 模式,加速对离线验证者的惩罚,以保障网络的稳定性
错误见证罚款:验证者支持了一条分叉链,导致其见证未能与网络共识一致。情节严重时,例如验证者被恶意行为者攻击或贿赂,故意支持错误的链头,可能会触发 惩罚退出(slashing),质押的 ETH 将被部分或全部销毁
- 典型的质押者下行风险:质押者可以通过比较潜在收益与惩罚来估算其下行风险。一个诚实的验证者一年内若获得10%的收益,可能因表现不佳而损失高达7.5%。短期不活跃会面临小额惩罚,而长时间离线则会招致更重的处罚
- 惩罚与举报奖励机制:惩罚机制针对严重违反协议的验证者实施,罚金从超过0.5 ETH直至全部质押金额不等。例如,若验证者做了违反规则的行为,将至少损失其余额的 1/32 并被停用。额外罚金则与同时受罚的验证者数量成正比。举报可罚行为的举报人将获得奖励,目前该奖励归区块提议者所有
- 提案者奖励:当区块提案者(proposers) 提议的区块被成功加入区块链并最终确定后,他们将获得丰厚的奖励。持续表现良好的验证者其总奖励大约增加1/8。此外,提案者若在其区块中包含惩罚证据,还能获得小额奖励
- 不活跃泄漏惩罚:不活跃泄漏是一种严厉的惩罚机制,旨在确保网络最终性。若最终性延迟超过四个 epoch,验证者将承受递增的惩罚,直至某个检查点被最终确认。此机制会耗尽不活跃验证者的余额,迫使其退出,从而使活跃验证者能够达到 2/3 大多数,网络恢复最终性。在不活跃泄漏期间,仅能获得提案者和举报者奖励,而证明者奖励为零
可能会被惩罚的行为
验证者可能遭受惩罚的四种情形如下:
- 重复提案:区块提案者(proposers)在被分配到的 Slot 中提议了多个区块
- LMD GHOST 重复投票:在同一个 Slot 上对不同的信标链头(Beacon Chain Head)进行投票
- FFG环绕投票:投出了一个环绕或被同一验证者之前的FFG投票所环绕的 FFG投票
译者注: 环绕指的是新的投票范围完全包裹了以前投票的范围,或反之。
示例:以前的 FFG 投票范围是 source: Epoch 3 -> target: Epoch 5。新的投票范围是 source: Epoch 2 -> target: Epoch 6。
问题:FFG 的目标是确保区块链最终性,环绕投票破坏了这种逻辑。可能被用来延迟最终性或操纵网络状态
- FFG 重复投票:在同一个 Epoch 内,验证者对不同的目标进行了两个 FFG 投票
信标链验证者激活与生命周期:
激活一个验证者需要32个ETH。若其余额降至16个ETH,验证者将被停用,剩余余额可提取。验证者在服务满2048个 epoch(约九天)后,亦可自愿退出。
退出时,需经历四个 epoch 的延迟方可提款,在此期间验证者仍可能遭受罚没.
信用良好的验证者可以在大约 27 小时内提取其余额,而受到处罚的验证者则需等待约36天(8192个 epoch)才能进行提款

为了防止验证者集合的快速变动,机制上限制了每个 epoch 内可以激活或退出的验证者数量。此外,信标链还采用了有效余额进行技术优化,其变动频率低于验证者的实际余额
译者注:
- 实际余额(Actual Balance):是验证者的真实账户余额,表示验证者账户上确切拥有的 ETH 数量,会随着质押奖励(或惩罚)的增加或减少而频繁变化。
- 有效余额(Effective Balance):是一个用于奖励和惩罚计算的平滑值,通常会向下取整到某个固定的单位(例如 1 ETH)。有效余额的变化频率比实际余额低
为什么需要有效余额?
- 减少频繁的状态更新: 如果直接使用实际余额进行奖励和惩罚计算,那么每次验证者的余额发生变化时,都会触发网络状态更新。状态更新是昂贵的,因为它需要被所有节点同步。使用有效余额可以限制状态更新的频率,从而降低网络的计算和通信成本。
- 提高计算效率: 奖励和惩罚通常按有效余额的比例计算。如果实际余额每次变化都需要重新计算,会增加复杂性。有效余额通过简化计算,提升网络运行效率。
- 平滑奖励和惩罚波动: 实际余额的频繁波动可能导致奖励或惩罚波动过大,影响验证者的经济预测。有效余额通过限制变化频率,使奖励和惩罚更平滑、更可预测
总体效果
每个 epoch 期间,验证者被均匀分配到各个 slot,并进一步细分为适当规模的委员会。验证者只能存在于一个 slot,且仅属于一个委员会。总体而言:
- 在一个 epoch 内,所有验证者都试图最终确认同一个检查点:FFG投票
- 分配给同一 slot 的所有验证者都尝试对相同的信标链头部进行投票:LMD GHOST投票,最优行为(对当前权重最大的链头进行投票)使验证者将获得最多的奖励
2020年12月1日,信标链启动时,初始拥有 21,063 名验证者。验证者数量可能因惩罚或自愿退出而减少,也可能有更多质押者加入并激活。时至今日(2024年5月15日),以太坊网络上活跃的验证者已超过1,000,000名。世界从未见过像以太坊这样可扩展的去中心化系统和应用平台。
引用资源
- Beacon Chain Explainer from ethos.dev
- Evolution of Ethereum Proof-of-Stake
- Alt Explainer, Ethereum's Proof-of-Stake consensus explained
- Eth2 Handbook by Ben Edgington
共识层(CL)架构
许多区块链共识协议都是可分叉的。可分叉的链使用分叉选择规则,有时会发生重组。
以太坊的共识协议结合了两个独立的共识协议。LMD GHOST 本质上提供活性。Casper FFG 提供最终性。这两者共同被称为 Gasper。
在一个活性协议中,好的事情总会发生。在一个安全协议中,坏的事情永远不会发生。没有任何实用的协议能够始终保持安全性的同时又始终保持活性。
分叉选择机制
如BFT中所述,由于各种原因 - 比如网络延迟、中断、消息乱序或恶意行为 — 网络中的节点可能会对网络状态有不同的认知。最终,我们希望每个诚实节点都能就一个相同的、线性的历史记录和系统状态的共同视图达成一致。协议的分叉选择规则正是帮助实现这种共识的机制。
区块树
基于区块树和节点对网络本地视图的决策标准,分叉选择规则旨在选择最有可能成为最终规范链的分支。它选择在节点收敛到共同视图时最不可能被剪枝的分支。

分叉选择规则从候选区块中选择一个头区块。头区块标识了一条从创世区块开始的唯一线性区块链。
分叉选择规则
分叉选择规则通过选择分支末端的区块(称为头区块)来隐式地选择一个分支。对于任何正确的节点来说,任何分叉选择的首要规则是:被选中的区块必须根据协议规则是有效的,并且它的所有祖先区块也必须是有效的。任何无效区块都会被忽略,基于无效区块构建的区块也是无效的。
以下是几个不同分叉选择规则的例子:
- 工作量证明(Proof-of-work):在以太坊和比特币中,使用"最重链规则"(有时被称为"最长链",但这种说法并不严格准确)。头区块是累积"工作量"最多的链的末端区块。
需要注意的是,与普遍的认知相反,以太坊的工作量证明协议并没有使用任何形式的 GHOST 作为分叉选择规则。这个误解一直存在,可能是因为以太坊白皮书的缘故。最终当 Vitalik 被问到这个问题时,他确认虽然在 PoW 下曾计划使用 GHOST,但由于担心某些未明确的攻击而从未实施。最重链规则更简单且经过充分测试,运行良好。
- Casper FFG (权益证明):在以太坊的 PoS Casper FFG 协议中,分叉选择规则是"遵循包含最高高度已证明检查点的链",并且永远不会回滚已最终确定的区块。
- LMD GHOST (权益证明):在以太坊的 PoS LMD GHOST 协议中,分叉选择规则是选择"最贪婪最重可观察子树"。这涉及计算验证者对区块及其子孙区块的累积投票。它同样也应用 Casper FFG 的规则。
这些分叉选择规则都会为区块分配一个数值分数。得分最高的区块即为头区块。目标是让所有正确的节点在看到某个区块时,都会认同它是头区块并跟随它的分支。这样,所有正确的节点最终都会就一条从创世区块开始的规范链达成一致。
重组和回滚
当节点接收到新的投票(在权益证明中包括对区块的新投票)时,它会根据这些新信息重新评估分叉选择规则。通常情况下,新区块会是当前头区块的子区块,并成为新的头区块。
然而,有时新区块可能是区块树中另一个区块的后代。如果节点没有这个新区块的父区块,它会向其对等节点请求该区块以及其他缺失的区块。
在更新后的区块树上运行分叉选择规则可能会显示,新的头区块位于与之前头区块不同的分支上。当这种情况发生时,节点必须执行重组(reorganisation)。这意味着它将移除(回滚)之前包含的区块,并采用新头区块所在分支上的区块。
例如,如果一个节点的链上有区块 和 ,并且它将 视为头区块,它知道有区块 的存在但在其当前的链视图中并不出现;该区块位于侧分支上。

此时,节点认为区块 是最佳头区块,因此它的链是区块
当节点随后收到构建在区块 上而不是当前头区块 上的区块 时,它必须决定是否应该将 作为新的头区块。举例来说,如果分叉选择规则表明 是更好的头区块,节点将回滚区块 和 。它会将这些区块从链上移除,就像从未收到过它们一样,并回退到区块 之后的状态。
然后,节点会将区块 和 添加到它的链上并处理它们。在这次重组之后,节点的链将包含 和 。

此时,节点认为区块 是最佳头区块,因此它的链必须改变为区块
后来,可能出现一个区块 ,它构建在区块 上,分叉选择规则说 应该是新的头区块,节点将再次重组,回滚到区块 并重新播放 分支上的区块。
由于网络延迟,一两个区块的短重组是很常见的。除非链遭受攻击,或者分叉选择规则及其实现存在漏洞,否则较长的重组应该很少发生。
安全性和活性
在共识机制中,有两个关键概念:安全性和活性。
安全性意味着"坏事永远不会发生",比如防止双重支付或确认冲突的检查点。它确保一致性,这意味着所有诚实节点应该始终对区块链的状态达成一致。
活性意味着"好事最终会发生",确保区块链始终能添加新的区块,永远不会陷入死锁状态。
CAP 定理指出没有分布式系统能够同时提供一致性、可用性和分区容错性。这意味着当通信不可靠时,我们无法设计出在所有情况下都既安全又活跃的系统。
以太坊优先保证活性
以太坊的共识协议旨在在良好的网络条件下同时提供安全性和活性。然而,在网络出现问题时,它优先保证活性。在网络分区的情况下,每个分区的节点都会继续产生区块,但无法达成最终确定性(这是一个安全性属性)。如果分区持续存在,每个分区可能会确定不同的历史记录,导致形成两条无法调和的独立链。
因此,虽然以太坊努力同时实现安全性和活性,但它倾向于确保网络保持活跃并继续处理交易,即使在严重的网络中断期间可能会带来潜在的安全性问题。
机器中的幽灵
以太坊的权益证明共识协议结合了两个独立的协议:LMD GHOST 和 Casper FFG。这两者共同被称为 "Gasper" 共识协议。关于这两个协议的详细信息以及它们如何协同工作将在下一节 [Gasper] 中详细介绍。
Gasper 旨在结合 LMD GHOST 和 Casper FFG 的优势。LMD GHOST 提供活性,通过定期产生新区块确保链持续运行。然而,它容易产生分叉且在形式上并不安全。另一方面,Casper FFG 通过定期对链进行最终确定来提供安全性,防止长程回滚。
本质上,LMD GHOST 保持链向前推进,而 Casper FFG 通过确定区块来确保稳定性。这种组合使以太坊能够优先保证活性,意味着即使 Casper FFG 无法确定区块,链仍然能继续增长。尽管这种组合机制并非完美且存在一些复杂性,但它是一个在实践中运行良好的工程解决方案。
架构
以太坊是一个由节点组成的去中心化网络,这些节点通过点对点连接进行通信。这些连接由运行以太坊客户端软件的计算机形成。

节点不需要运行验证者客户端(绿色节点)就可以成为网络的一部分,但是要参与共识,则需要质押 32 ETH 并运行验证者客户端。
共识层的组件
-
信标节点:信标节点使用客户端软件来协调以太坊的权益证明共识。例如 Prysm、Teku、Lighthouse 和 Nimbus。信标节点与其他信标节点、本地执行节点以及(可选的)本地验证者进行通信。
-
验证者:验证者客户端是允许人们在以太坊共识层质押 32 ETH 的软件。验证者在权益证明系统中负责提议区块,取代了工作量证明中的矿工。验证者只与本地信标节点通信,后者为其提供指令并将其工作广播到网络中。
承载真实应用的主要以太坊网络被称为以太坊主网。以太坊主网是以太坊的实时生产环境,用于铸造和管理真实的以太币(ETH)并具有实际货币价值。
此外还有测试网络,用于铸造和管理测试用的以太币,供开发者、节点运营者和验证者在使用主网真实 ETH 之前测试新功能。每个以太坊网络都有两层:执行层(EL)和共识层(CL)。每个以太坊节点都包含这两层的软件:执行层客户端软件(如 Nethermind、Besu、Geth 和 Erigon)和共识层客户端软件(如 Prysm、Teku、Lighthouse、Nimbus 和 Lodestar)。

共识层负责维护共识链(信标链)并处理从其他对等节点接收到的共识区块(信标区块)和证明。共识客户端参与一个独立的点对点网络,其规范与执行客户端不同。它们需要参与区块传播以接收来自对等节点的新区块,并在轮到它们提议时广播区块。
执行层和共识层客户端并行运行,需要保持连接以进行通信。共识客户端向执行客户端提供指令,执行客户端则将交易包传递给共识客户端以包含在信标区块中。通信通过本地 RPC 连接使用 Engine-API 实现。它们共享一个 ENR,但每个客户端使用独立的密钥(eth1 密钥和 eth2 密钥)。
控制流程
当共识客户端不是区块生产者时:
- 通过区块 gossip 协议接收区块。
- 对区块进行预验证。
- 将区块中的交易作为执行负载发送到执行层。
- 执行层执行交易并验证区块状态。
- 执行层将验证数据发送回共识层。
- 共识层将区块添加到其区块链中并对其进行证明,将证明广播到网络中。
当共识客户端是区块生产者时:
- 收到成为下一个区块生产者的通知。
- 调用执行客户端中的创建区块方法。
- 执行层访问交易内存池。
- 执行客户端将交易打包成区块,执行它们,并生成区块哈希。
- 共识客户端将交易和区块哈希添加到信标区块中。
- 共识客户端通过区块 gossip 协议广播区块。
- 其他客户端验证区块并对其进行证明。
- 一旦得到足够验证者的证明,区块就会被添加到链头,被证明合理性并最终确定。
状态转换
状态转换函数在区块链中至关重要。每个节点维护一个反映其对世界认知的状态。
节点通过按顺序应用区块使用"状态转换函数"来更新它们的状态。这个函数是"纯函数",意味着其输出仅依赖于输入且没有副作用。因此,如果每个节点从相同的状态(创世状态)开始并应用相同的区块,它们最终都会得到相同的状态。如果不是这样,就说明出现了共识失败。
如果 是信标状态, 是信标区块,则状态转换函数 为:
这里, 是前置状态, 是后置状态。函数 随着每个新区块的到来而迭代执行以更新状态。
信标链状态转换
与区块驱动的工作量证明不同,信标链是槽驱动的。状态更新取决于槽的进展,而不依赖于区块是否存在。
信标链的状态转换函数包括:
- 每槽转换:
- 每块转换:
- 每周期转换:
每个函数都按照信标链规范中定义的特定时间更新链。
有效性条件
从前置状态和已签名区块得到的后置状态是通过 state_transition(state, signed_block) 计算的。导致未处理异常(例如,断言失败或越界访问)或 uint64 溢出/下溢的转换都是无效的。
信标链状态转换函数
从前置状态 state 和已签名区块 signed_block 得到的后置状态是通过 state_transition(state, signed_block) 定义的。触发未处理异常(例如,assert 断言失败或列表越界访问)的状态转换被视为无效。导致 uint64 溢出或下溢的状态转换也被视为无效。
def state_transition(state: BeaconState, signed_block: SignedBeaconBlock, validate_result: bool=True) -> None:
block = signed_block.message
# Process slots (including those with no blocks) since block
process_slots(state, block.slot)
# Verify signature
if validate_result:
assert verify_block_signature(state, signed_block)
# Process block
process_block(state, block)
# Verify state root
if validate_result:
assert block.state_root == hash_tree_root(state)
def verify_block_signature(state: BeaconState, signed_block: SignedBeaconBlock) -> bool:
proposer = state.validators[signed_block.message.proposer_index]
signing_root = compute_signing_root(signed_block.message, get_domain(state, DOMAIN_BEACON_PROPOSER))
return bls.Verify(proposer.pubkey, signing_root, signed_block.signature)
def process_slots(state: BeaconState, slot: Slot) -> None:
assert state.slot < slot
while state.slot < slot:
process_slot(state)
# Process epoch on the start slot of the next epoch
if (state.slot + 1) % SLOTS_PER_EPOCH == 0:
process_epoch(state)
state.slot = Slot(state.slot + 1)
Resources
- Vitalik Buterin, "Parametrizing Casper: the decentralization/finality time/overhead tradeoff"
- Engine API spec
- Vitalik's Annotated Ethereum 2.0 Spec
- Ethereum, "Eth2: Annotated Spec"
- Martin Kleppmann, Distributed Systems.
- Leslie Lamport et al., The Byzantine Generals Problem.
- Austin Griffith, Byzantine Generals - ETH.BUILD.
- Michael Sproul, "Inside Ethereum"
- Eth2 Handbook by Ben Edgington